Ricapitolando brevemente, i metodi di compressione possono essere conservativi e non. I formati ZIP, GIF e PNG comprimono i dati in maniera rigorosamente conservativa mentre JPEG, MP3 e MP4 impiegano anche una componente di compressione non conservativa. Rammentiamo anche che ZIP serve a archiviare in forma compressa qualsiasi cosa – testi, dati, software ecc. – GIF, PNG e JPEG sono sistemi di codifica di immagini, MP3 e MP4 codificano informazioni audio e video rispettivamente.
Con i metodi conservativi si comprimono i dati sfruttando eventuali ripetizioni in essi – la decompressione in questo caso fornisce una copia perfetta dei dati originali e il fattore di compressione dipende dalla loro natura: se sono presenti molte ripetizioni allora la compressione è più efficace.
È facile comprendere come la ripetizione dei dati possa essere sfruttata ai fini della compressione. Facciamo un esempio banale. Supponiamo di avere un file di testo contenente solo una sequenza ininterrotta di caratteri “A” e supponiamo che questi siano 1 milione. Poiché ogni carattere viene codificato in un byte, il file risulterà lungo 1 milione di byte. Ora, applichiamo una compressione “fai da te” dove assumiamo che, quando una lettera dell’alfabeto è immediatamente seguita da un numero, allora la lettera deve essere ripetuta quel preciso numero di volte, ad esempio: “A5” significa “AAAAA”. Ecco, applicando una codifica del genere, il nostro file (demenziale), una volta compresso in questo modo, conterrebbe solo il testo “A1000000”. In questo esempio la compressione sarebbe vigorosa: da 1 milione di byte saremmo scesi agli 8 byte che servono a codificare la sequenza di caratteri “A100000”! Naturalmente, questo esempio è lontano dagli schemi che vengono applicati dai sistemi di compressione conservativa reali, che sono ben più sofisticati, ma serve perfettamente per capire il concetto. Serve anche a capire come il fattore di compressione possa dipendere molto dalla natura dei dati: applicando il suddetto metodo a un testo reale lungo 1 milione di byte, probabilmente otterremmo una compressione molto ridotta, di poco inferiore a 1 milione di byte.
I metodi non conservativi invece comprimono i dati eliminando parte dell’informazione, tout court. L’idea si basa sul fatto che probabilmente non tutta l’informazione presente verrà utilizzata effettivamente. È un’idea che si può applicare ai suoni e alle immagini e sfrutta i limiti percettivi e cognitivi di chi ascolta i suoni o guarda le immagini. Non si tratta banalmente di sbarazzarsi di alcune parti delle immagini o alcune sezioni di un brano musicale – questo sarebbe davvero poco soddisfacente – ma di aspetti che si suppone i fruitori di quelle informazioni non percepiscano.
La mano è sempre quella di Michelangelo ma le differenze sono molte: ad esempio il primo volto è un affresco mentre il secondo una tempera su tavola, la prima immagine è una scansione tratta da un libro d’arte [1] mentre la seconda è un’immagine presa da Wikipedia [2]. Ma le numerose e rilevanti differenze dipendenti dalla diversa natura delle opere e delle loro riproduzioni non nascondono il modo assai diverso con cui Michelangelo ha realizzato questi due ritratti, dove il primo sembra quasi uno schizzo preparatorio rispetto all’esecuzione completamente rifinita del volto della Madonna.
Ebbene, questa è la compressione non conservativa di Michelangelo. La volta della Cappella Sistina si trova a circa 13 metri dal pavimento e questo pone un limite alla capacità di vedere ad occhi nudo piccoli dettagli, che sono invece apprezzabili in un dipinto che può essere visto molto da vicino. Michelangelo ha quindi dipinto “meno informazione” in quelle situazioni in cui sapeva che nessuno le avrebbe potute apprezzare – in condizioni normali – ottenendo così una compressione delle informazioni fondamentale: se avesse inteso dipingere tutta la volta con la stessa accuratezza del Tondo Doni ci avrebbe messo ben più dei quattro anni che gli sono occorsi, e forse anche la salute… [3].
I' ho già fatto un gozzo in questo stento,
come fa l'acqua a' gatti in Lombardia
o ver d'altro paese che si sia,
c'a forza 'l ventre appicca sotto 'l mento.
La barba al cielo, e la memoria sento
in sullo scrigno, e 'l petto fo d'arpia,
e 'l pennel sopra 'l viso tuttavia
mel fa, gocciando, un ricco pavimento
E' lombi entrati mi son nella peccia,
e fo del cul per contrapeso groppa,
e' passi senza gli occhi muovo invano.
Dinanzi mi s'allunga la corteccia,
e per piegarsi adietro si ragroppa,
e tendomi com'arco sorïano.
Però fallace e strano
surge il iudizio che la mente porta,
ché mal si tra' per cerbottana torta.
La mia pittura morta
difendi orma', Giovanni, e 'l mio onore,
non sendo in loco bon, né io pittore.
Quindi Michelangelo ha approssimato JPEG? Semmai il contrario! Per applicare una compressione non conservativa nel migliore dei modi occorrerebbe il massimo dell’intelligenza, cosa che non si può richiedere ad un sistema automatico. Per questo si deve stare attenti a dosare la compressione di JPEG, mettendo almeno un pochino di intelligenza nel salvare un’immagine in tale formato. Si vada per tentativi, magari figurandosi l’impiego che ne dovrà esser fatto: un conto è un’immagine che deve essere vista in un piccolo formato su un monitor, un conto è inviare un’immagine da stampare in un grande formato. Chiaro che il primo è il caso di gran lunga più frequente: perfettamente inutile lasciare i setting di massima qualità nell’applicazione di fotografia del telefonino, considerato l’uso prevalente (e ridondante) di quelle foto…
Per lo stesso motivo, un musicista potrebbe non gradire la riproduzione MP3 di un brano musicale: un conto è un pezzo heavy metal e un altro una sonata per violino di Bach…
Non s’è preteso di spiegare molto. Per comprendere in maniera più approfondita il meccanismo della compressione non conservativa, occorrerebbe avventurarsi nei territori dell’analisi di Fourier. Tuttavia ci illudiamo così di avere dato un’idea anche a chi quei territori non li ha mai vistati o è tanto tempo che non vi è tornato.
[1] Michelangelo – Leben und Werk – Belser Verlag, Stuttgart, 1989, pag 86
[2] L’opera d’arte mostrata in questa immagine è nel pubblico dominio per via della data del decesso del suo autore (la norma si applica all’Unione europea, agli Stati Uniti e a tutti quei paesi in cui il copyright scade 70 anni dopo la morte dell’autore).
Clicca qui per scaricare la versione in pdf (1.8MB)
Sicuramente un post per gli studenti di “Editing multimediale” della IUL ma anche per tutti quelli a cui capita di lavorare con le immagini
Grafica bitmap e vettoriale
Due o tre cose sui formati più noti, GIF, PNG e JPEG, sulla compressione delle informazioni, conservativa e non, e sui formati “dedicati” XCF e SVG
Gimp e Inkscape, due bellissimi software liberi per l’elaborazione delle immagini che girano su Linux, Mac e Windows
Elaborazione delle immagini in livelli
Primo fatto: software libero anziché proprietario
Il fatto che il software sia libero o proprietario è fondamentale, per motivi etici prima ancora che tecnici. L’espressione sintetica di Marina è perfetta:
software libero vuol dire che rende le persone più libere
Aggiungo: la scuola e l’università hanno il dovere morale di dimostrare, diffondere e promuovere il software libero. Il resto l’abbiamo detto in un post precedente.
Secondo fatto: distinguere fra grafica bitmap e vettoriale
Immagini digitali
Le immagini digitali sono sempre formate da una sorta di scacchiera di piccoli quadratini denominati pixel, il cui interno è rappresentato con un colore uniforme al quale nel computer corrisponde un certo valore numerico. Anche se le immagini sono monocromatiche vale lo stesso concetto. Per fare un esempio noto a tutti, le immagini TAC (Tomografia Assiale Computerizzata) sono rappresentate in scale di grigi. Ebbene, anche lì in ogni pixel, l’intensità di grigio è in relazione con un numero che rappresenta (con una certa approssimazione) la densità media dei tessuti del corpo nella spazio rappresentato da quel pixel.
dpi e risoluzione
In qualsiasi immagine digitale potete scorgere i pixel, se vi avvicinate o la ingrandite a sufficienza. Naturalmente è proprio quello che non si vuole vedere, di solito. In questo articolo useremo il termine risoluzione per il numero di pixel dell’immagine – maggiore risoluzione significa maggior numero di pixel. In realtà, il concetto di risoluzione spaziale di un’immagine è differente e molto più complesso ma qui ci atterremo alla prassi corrente per rendere il discorso più agile e compatto. Invece con dimensione intenderemo la grandezza del file in cui l’immagine viene memorizzata, e potrà essere espressa in Mega Byte (MB) o in Kilo Byte (KB) [1].Per esempio se fate una scansione di un documento o un’immagine dovete fare attenzione al parametro dpi (dots per inch, punti per pollice). Un pollice sono 2.54 cm e valori accettabili stanno usualmente fra 100 e 200 dpi, ma dipende da cosa dovete scannerizzare. Occorre quindi fare delle prove scegliendo il valore più basso che dà la qualità adeguata, nel contesto che vi interessa. Non vale esagerare, perché la dimensione delle immagini cresce grandemente in proporzione inversa alle dimensioni dei pixel: se i pixel di un’immagine sono più piccoli vuol dire che ve ne saranno di più – se scelgo 200 dpi anziché 100, vuol dire che su ogni lato dell’immagine ho il doppio dei pixel, quindi il numero totale dei pixel dell’immagine sarà 2×2=4 volte più grande, ergo raddoppiare la dimensione lineare vuol dire quadruplicare la dimensione dell’immagine, e quindi anche la dimensione del file dove questa viene memorizzata. Infatti, dal punto di vista del computer, un’immagine digitale è semplicemente una fila di numeri, tanti quanti sono i pixel in cui è suddivisa. Quando il computer la deve rappresentare su un qualche supporto – monitor, stampa… – allora legge i numeri a partire dal primo e decodifica ciascuno di essi in maniera da produrre l’effetto dovuto, in termini di colore e intensità, poi li “scrive” nello spazio dell’immagine come si fa nelle lingue occidentali: da sinistra a destra, dall’alto al basso.
Tipi di grafica
Ma non sempre le immagini vengono memorizzate secondo la logica di un “elenco dei contenuti dei pixel”. Si danno infatti due possibilità, una che prende il nome di grafica vettoriale e l’altra di grafica bitmap, o grafica raster (raster: griglia; da qui in poi utilizzeremo il termine bitmap). Le immagini bitmap sono memorizzate così come abbiamo già detto. Ad esempio le fotografie e le immagini mediche sono di questo tipo. Le immagini vettoriali sono invece memorizzate attraverso una rappresentazione ad oggetti. I disegni CAD (Computer Assisted Design) fatti da un progettista e i documenti PDF sono esempi di immagini vettoriali. Facciamo un esempio affinché la differenza sia chiara.
Grafica bitmap
Supponiamo prima di disegnare una circonferenza con un software di tipo bitmap, poi immaginiamo di ingrandire molto l’immagine: prima o poi la circonferenza rivelerà la struttura in pixel, che le darà un aspetto frastagliato.
Immagine di una circonferenza generata in grafica bitmap. L’immagine di destra rappresenta l’ingrandimento del quadrato rosso raffigurato nell’immagine di sinistra.
Grafica vettoriale
Disegnate ora la stessa circonferenza con un software di tipo vettoriale e provate a ingrandire l’immagine a piacimento: la circonferenza sarà sempre lì, con gli stessi identici attributi che le avrete assegnato all’atto della sua creazione. Magari ne vedete solo un piccolo arco perché avete ingrandito l’immagine veramente tanto, ma non vi sono artefatti.
Immagine di una circonferenza generata in grafica vettoriale. L’immagine di destra rappresenta l’ingrandimento del quadrato rosso raffigurato nell’immagine di sinistra.
Perché questa differenza? Il software di tipo bitmap parte da un’immagine che è tanti pixel alta e tanti pixel larga. Dopodiché qualsiasi cosa facciate, il software si preoccupa di riempire i pixel come dite voi. Altro non fa. Se avete chiesto di disegnare una circonferenza, il sistema utilizza l’equazione matematica della circonferenza
dove α e β sono le coordinate del centro e r è il raggio della circonferenza, per riempire appropriatamente i pixel. Poi se ne dimentica, ovvero dimentica i suoi parametri, α, β e r [2]. Invece, il software di tipo vettoriale, utilizza l’equazione della circonferenza per disegnarla sullo schermo, con i parametri di rappresentazione correnti, ovvero riempie i pixel che voi vedete sullo schermo, e invece di memorizzarne i contenuti memorizza l’equazione della circonferenza, sotto forma dei suoi parametri α, β e r, e di altri eventuali attributi grafici, quali spessore e colore della linea. Poi, ogni volta che voi rinfrescate l’immagine sullo schermo, ricaricandola o variandone le dimensioni, ricalcola i contenuti dei pixel a partire dall’equazione della circonferenza. E così per tutti gli altri oggetti.
Riassumendo, con la grafica bitmap il sistema ricorda i contenuti di tutti i pixel dell’immagine – quando la deve rappresentare sul schermo costruisce l’immagine semplicemente rappresentando adeguatamente i singoli pixel. Con la grafica vettoriale il sistema ricorda l’idea di circonferenza, ovvero di quella precisa circonferenza con il centro posizionato in quella certa posizione, con quel certo raggio, con quel certo spessore e quel certo colore con cui deve essere tracciata – quando deve rappresentare l’immagine, prima calcola i contenuti dei pixel per rappresentare quella circonferenza, poi rappresenta i pixel così calcolati sullo scheermo.
Formati – compressione
Non vogliamo perderci qui nella foresta dei formati. Se necessario approndiremo dove opportuno. Solo gli esempi comuni. Tutte le immagini di origine fotografica sono gestite e memorizzate con la logica bitmap. È naturale: derivano tutte da una qualche matrice di rivelatori, intendendo per matrice una qualche precisa disposizione di rivelatori di radiazione elettromagnetica: luminosa, infrarossa, X o altro. I formati più comuni per la distribuzione di immagini bitmap nel web sono GIF, PNG e JPEG – detto anche JPG, è lo stesso.
Qui occorre un inciso sulla compressione. Le immagini – anche l’audio e a maggior ragione il video – contengono molta informazione, quindi i file tendono ad essere grandi – oggi si ama dire che sono “pesi”. Persino la fotocamera di un telefono produce immagini di vari milioni di pixel. Far viaggiare questa roba in internet può essere un problema, a maggior ragione per chi vive in paesi sottosviluppati – o “diversamente sviluppati”, come il nostro, duole dirlo ma all’atto pratico, fra la velocità di trasferimento subalpina e quella sovralpina può corre tranquillamente un fattore 10. Le tecniche di compressione dell’informazione sono quindi fondamentali, è grazie a queste che la distribuzione dell’informazione multimediale è esplosa, ad esempio nei formati MP3 (audio), JPEG (immagini) e MP4 (video). Tutti questi esempi – sono i più comuni ma ve ne sono tanti altri – sono caratterizzati dal fatto di impiegare un qualche sistema di compressione dell’informazione. E tutti e tre usano i sistemi di compressione più efficaci, ovvero quelli non conservativi, che per comprimere meglio buttano via qualcosa – qualcosa che non si sente nell’audio, che non si vede nelle immagini o nei video. Sono sistemi regolabili – se si esagera si finisce col deteriorare il messaggio.
Con la compressione conservativa invece non si butta via nulla, ma si sfruttano ripetizioni e regolarità, sfruttandole in modo intelligente. Ci capiamo subito con questo esempio: pensate a un’immagine fatta da un solo pixel centrale nero e tutti gli altri bianchi – non è interessante ma è utile per capire. Non è difficile immaginare un sistema abbastanza furbo da memorizzare il numero di pixel che sono uguali e il loro (unico) valore. Nel nostro esempio significa che invece di memorizzare milioni di numeri, basta memorizzare il numero dei pixel bianchi, il numero di quelli neri e i due valori corrispondenti al bianco e al nero: 4 numeri! Abbiamo semplificato molto ma il concetto c’è, ed è anche sufficiente a capire che il successo di questi metodi dipende dal tipo di immagine. Per esempio in un’immagine fotografica piena di sfumature morbide ci sarà poco da comprimere. Un esempio di compressione conservativa molto noto è quello del formato ZIP. Può valer la pena di fare un giochino. Prendo un brano di questo scritto, lo salvo in un file con un editore di testo – un editore di testo, non Word! – Mi è venuto un file di 1075 byte. Sempre con l’editore di testo scrivo “pippo pippo…” tante volte (alla Shining – non mi sta vedendo nessuno…) fino a ottenere un file egualmente lungo, ovvero di 1075 byte. Applico a tutti e due lo zip: nel primo caso viene un file di 725 byte e nel secondo di 173 byte. Potete provare anche voi per esercizio, inventandovi degli esempi simili, o scaricando il file numero 1 e il file numero 2 per zipparli da voi.
Dunque dicevamo che i formati più comuni per la distribuzione di immagini bitmap nel web sono, GIF, PNG e JPEG. Vediamoli brevemente.
Il formato GIF usa una compressione conservativa. Questo lo rende adatto a immagini che contengono testo o grafica composta da linee. Si può usare per fare immagini animate.
Anche il formato PNG comprime l’immagine in modo conservativo e quindi anche questo è adatto nei casi cui sono presenti testo o linee. È meglio rispetto al GIF perché è più recente: consente di rappresentare le immagini con maggiore qualità e le comprime meglio. Non si possono però fare immagini animate, per questo ci vuole il formato GIF. In fondo vedremo un esempio.
Il formato JPEG applica invece una compressione non conservativa. È il formato adatto alle immagini fotografiche. Se siamo noi a generare un file JPEG, allora all’atto del salvataggio si può scegliere il grado di compressione. Occorre controllare quindi: più si comprime e più l’immagine può risultare degradata, specialmente se vi sono dettagli fini e contrasti bruschi.
Per quanto riguarda la grafica vettoriale occorre certamente citare il PDF. È un’ottima occasione per puntualizzare che il PDF è un formato grafico, e per di più vettoriale, perché molti scambiano il PDF per una variante del formato DOC – quello di Word, o altri word processor. No, il PDF non è un formato di testo o testo formattato, bensì è un formato grafico: esportare un documento qualsiasi – testo, foglio di lavoro o altro – in PDF vuole dire farne una sorta di fotografia, ovvero congelarlo in un’immagine, e per di più un’immagine vettoriale, perché così risulta meno sensibile alla modalità con la quale viene rappresentato, grazie al meccanismo ad oggetti che abbiamo visto. Perché il PDF è nato proprio per diffondere documenti nella rete, in maniera che questi rimangano inalterati, indipendente dal supporto di visualizzazione o dalla modalità di stampa.
Manipolando foto
La questione del formato è particolarmente importante quando siamo noi che creiamo le immagini. Le immagini si possono presentare in una grande varietà di forme, agli estremi abbiamo le fotografie da un lato e i “disegni al tratto” dall’altro – diagrammi, grafici. Di foto ne produciamo tutti tante, anche troppe. La tendenza è scattare e riempire memorie – pensa a tutto la macchina. In realtà anche in un cellulare di fascia bassa si può intervenire su alcuni parametri, per non parlare degli smartphone. Sicuramente si possono determinare numero di pixel e qualità dell’immagine. La dimensione dei file cresce con il numero dei pixel e la qualità dell’immagine. La qualità è di fatto regolata mediante il rapporto di compressione JPEG. Prima di usare l’apparecchio, non sarebbe male fare delle prove, ripetendo lo stesso scatto con risoluzioni e qualità diverse, per poi scegliere i parametri che consentono di ridurre le dimensioni dei file ma senza introdurre artefatti nell’immagine.
Chi ha qualche velleità fotografica e utilizza macchine “serie” – reflex, street photography, grandi formati – ha certamente a disposizione l’opzione del formato cosiddetto RAW –raw data: dati grezzi. Questi sono i numeri letti direttamente dai sensori dell’apparecchio, sui quali si può lavorare successivamente con gli appositi software di elaborazione fotografica. È il formato prediletto da chi vuol partecipare alla costruzione dell’immagine fotografica, un po’ come coloro che amavano sviluppare le proprie foto nella camera oscura. Con il formato RAW la libertà di espressione è maggiore ma anche la dimensione dei file è molto più grande dei file JPEG – meno scatti, più riflessione post processing – ex camera oscura – più qualità.
Fabbricando immagini
Diverso è il caso in cui le immagini ce le dobbiamo fabbricare “a mano”. Qui la risposta non è univoca perché dipende da quello che si deve fare. Nel caso di diagrammi o grafici, quasi certamente conviene optare per un formato di tipo vettoriale. Costruendo invece immagini composite nelle quali gli elementi fotografici sono importanti, allora probabilmente si può lavorare sia in forma vettoriale che bitmap – la scelta dipende dal tipo di fruizione dei risultati e, in ultima istanza, dalle preferenze personali.
Lavorare in forma grafica bitmap o vettoriale vuol dire usare software diversi. Qui citiamo due ottimi software liberi: Gimp per la grafica bitmap e Inkscape per la grafica vettoriale. La quantità e varietà di software e di servizi web per l’elaborazione delle immagini è impressionante. Molti conosceranno Photoshop per il ritocco delle immagini fotografiche, e forse avranno sentito nominare Autocad per la progettazione, quali esempi di software per grafica bitmap da un lato e vettoriale dall’altro, anche se quest’ultimo più di nicchia e strettamente professionale. Sono programmi dal prezzo elevato, probabilmente ingiustificato per la maggioranza delle finalità che può avere un utente generico. In realtà le alternative libere Gimp e Inkscape sono molto sofisticate e possono essere usate con profitto anche in contesti professionali. Gli esempi precedenti, dove abbiamo mostrato cosa succede ingrandendo immagini dei due tipi sono stati realizzati con questi due software, ma vediamo qualche esempio per dare un’idea delle potenzialità e delle differenze fra le due modalità.
Lavorare in grafica bitmap con Gimp
.
Questa immagine – chi vuole sapere di che si tratta può leggere la nota [3] – è stata è stata scattata con un apparecchio comune, di quelli automatici, nemmeno più tanto recente, e ciò nonostante già in grado di sparare immagini di 4320×3240 pixel, come questa che vedete qui sopra, espressa in tre diversi formati, da sinistra a destra: PNG – compressione conservativa, cioè nessun degrado ma il file occupa 19MB; JPEG con compressione ridotta (94% di qualità secondo Gimp [4]) , e già così si ottiene un file di soli 3 MB; JPEG con compressione elevata, (10% di qualità sempre secondo Gimp), e si arriva a 213 KB: un fattore di compressione dell’1% e la qualità sembra la stessa! In effetti, con così tanti pixel si può andar giù pesanti con la compressione JPEG.
Ma la differenza c’è, dipende da come si intende usare l’immagine, in particolare da quanto si pensa di ingrandirla. Le tre immagini sopra sono scalate per farle entrare nel post, cliccando sopra appaiono le versioni originali, sulle quali potete cliccare un’altra volta per ingrandirle ulteriormente. Se con il vostro browser non funziona così, potete scaricarle sul vostro computer e poi ingrandirle con il software di visualizzazione di immagini che usate di solito. Ebbene, vedrete che, ingrandendo molto, se fra le versioni PNG (a sinistra) e JPEG 94% (quella di mezzo) non ci sono differenze apprezzabili, la versione JPEG 10% (a destra) risulta marcatamente degenerata, con una sorta di artefatto a blocchi. Ebbene quello è l’effetto di perdita di informazione, causato da una compressione JPEG troppo aggressiva. Dipende quindi da come si vogliono utilizzare le immagini.
Ma vediamo ancora più in dettaglio come stanno le cose, confrontando un particolare dell’immagine senza alterazioni, con risoluzione ridotta, con compressione JPEG e con tutti e due i trattamenti.
1) immagine originale ad alta risoluzione 4320×3240 pixel, dimensione 19 MB; 2) sempre ad alta risoluzione ma molto compressa con JPEG, dimensione 213 KB; 3) a risoluzione ridotta del 20%, 864*648 pixel, dimensione 211 KB: 4) sia a risoluzione ridotta che molto compressa con JPEG, dimensione 23 KB. Clicca l’immagine per vedere gli effetti, poi clicca ancora sull’immagine che viene per zoomarla e vedere bene gli effetti.
Per vedere bene gli effetti occorre cliccare sull’immagine qui sopra, che è scalata per farla entrare nell’impaginazione, e poi cliccare nuovamente sull’immagine che appare per ingrandirla ulteriormente.
Ebbene, se la dimensione del file dell’immagine originale era di 19 MB, sia riducendo la risoluzione del 20% che applicando una compressione JPEG energica – 10% secondo Gimp – questa si riduce a circa 200 KB, ovvero dell’1%, e in ambedue i casi si osservano delle degenerazioni, che sono però di natura diversa. Applicando infine ambedue i trattamenti, si riduce sì di un ordine di grandezza la dimensione del file (23%) ma addio qualità.
Quindi, primo messaggio: per ridurre il “peso” di un’immagine si può agire sul parametro di qualità-compressione del formato JPEG ma occhio alla risoluzione: se i pixel sono pochi il rischio di rovinare l’immagine è alto, quindi bisogna essere prudenti: andare per tentativi e errori.
Secondo messaggio: per lavorare bene, può avere senso porsi il problema se convenga ridurre le dimensioni riducendo la risoluzione oppure comprimendo di più con il JPEG. Si confrontino le immagini 2), compressa con JPEG, e 3), alleggerita riducendo la risoluzione. La prima ha i contorni più conservati mentre si sono praticamente perse le sfumature delle superfici piane. Nella seconda le sfumature delle superfici sono ancora ben rappresentate ma i contorni sono deteriorati dalla dimensione dei pixel – meno pixel vuol dire pixel più grossi. Da tutto questo si vede come in ambedue i casi la riduzione delle dimensioni dell’immagine sia stata ottenuta al prezzo della perdita di una certa quantità di informazione, ma che tale perdita è qualitativamente diversa nei due casi. La riduzione della risoluzione tende a sciupare i contorni, la compressione JPEG tende a sparpagliare la degenerazione nell’immagine. L’indicazione pratica che se ne ricava è che nel caso di immagini morbide e con poche variazioni brusche di contrasto conviene ridurre la risoluzione, ovvero il numero di pixel; invece nel caso di immagini dove predominano linee e contorni forti, può convenire ricorrere ad una compressione JPEG più energica. In ogni caso: domandarsi come verrà usata l’immagine e cosa vogliamo comunicare e poi andare per tentativi ed errori, perché gli effetti cambiano a seconda del tipo di immagine.
Chi si cimenta nell’uso di Gimp si accorge che fra i 40 formati nei quali può salvare un’immagine, il primo che viene proposto è XCF. Questo è il formato nativo di Gimp, ovvero quello che è in grado di memorizzare tutte le informazioni fra una sessione di lavoro e l’altra. È il formato da usare quando si lavora con un’immagine e la vogliamo mantenere per ritornarci a lavorare in futuro – se la memorizziamo in questo formato siamo sicuri di ritrovare tutta quello che abbiamo fatto in precedenza. Non è il formato da usare per inviare un’immagine in rete, a meno che uno non voglia condividerla con qualcun altro che debba continuare a lavorarci con Gimp. Il processo corretto quindi è quello di memorizzare tutte le varie versioni dello sviluppo in XCF e poi esportare il risultato in un formato idoneo a essere trasmesso, per esempio GIF, PNG, JPEG o altro.
Resterebbe da dire qualcosa sulle elaborazioni in grafica bitmap, ma vedremo meglio dopo, ragionando del terzo fatto che fa la differenza, in materia di manipolazione di immagini.
Lavorare in grafica vettoriale con Inkscape
Le immagini si possono creare anche in grafica vettoriale. Anche per questo tipo di elaborazione esiste uno splendido software libero, che è Inkscape. Vediamo un esempio.
Esempio di tipica immagine che conviene produrre in grafica vettoriale. Questa è stata prodotta con il software libero Inkscape. Clicca l’immagine per vederla meglio.
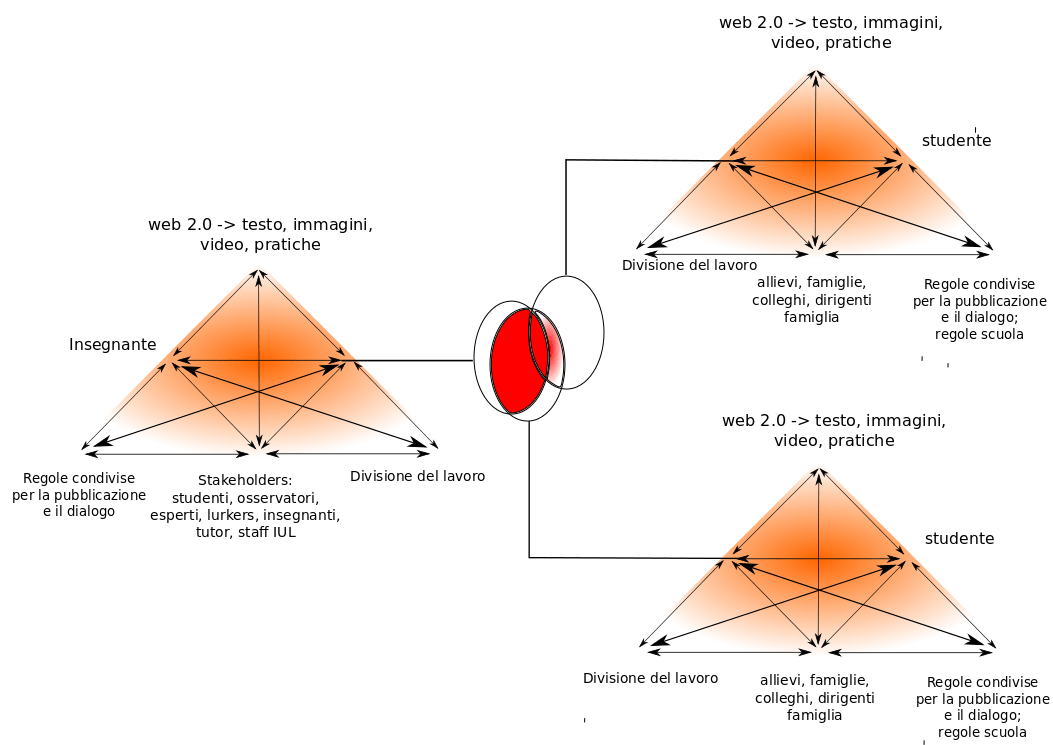
Il soggetto dell’immagine non ci interessa qui, se non per come è stato costruito graficamente. Chi fosse incuriosito dal senso del diagramma può leggere una breve nota [5]. Come abbiamo già visto, nella modalità vettoriale, ad essere memorizzati non sono i pixel dell’immagine ma le caratteristiche geometriche degli oggetti – in questo caso triangoli, ellissi, segmenti di vario tipo, sfondi, testi. È una modalità comodissima per fabbricare un diagramma del genere. Una volta costruito un triangolo, con le sue frecce, il suo sfondo e i testi, per fare gli altri, basta raggruppare tutti gli elementi con una semplice riquadratura e duplicare il tutto, spostare la copia nella posizione desiderata e poi intervenire sui singoli elementi che debbano essere eventualmente cambiati, per esempio i testi in questo caso. Ciò è reso possibile dal fatto che il sistema tiene traccia di ogni singolo oggetto e di ogni sua caratteristica, in un modo che rende molto semplice manipolarlo, riprodurlo e nuovamente alterarlo in ogni successiva fase del lavoro:
Esempio di come, in grafica vettoriale, sia facile selezionare un gruppo di oggetti, per poi spostarlo, replicarlo o modificare in ogni suo componente. Cliccare l’immagine per vederla meglio.
Fra i casi estremi che abbiamo mostrato esiste tutta una zona intermedia di risultati che possono essere raggiunti con ambedue i sistemi. Per averne un’idea può essere interessante andare a vedere in DeviantART – un social network dedicato alle creazione grafiche – i lavori fatti sia dagli appassionati di Gimp che da quelli di Inkscape.
Anche Inkscape ha un formato di riferimento che conserva tutto ciò che serve per conservare il lavoro fra sessioni successive, è lo SVG. Valgono le stesse considerazioni fatte a proposito del formato XCF di Gimp. La differenza con Gimp è che Inkscape non offre formati che comprimono in modo non conservativo – per esempio si può salvare in PNG ma non in JPEG. Del resto, se vogliamo, il formato vettoriale opera intrinsecamente una forma di compressione, memorizzando solo i parametri geometrici degli elementi presenti anziché i contenuti dei pixel, che sono quasi sempre centinaia di migliaia o milioni. Ad esempio, l’immagine precedente, che è anche abbastanza complessa, è composta da 780’000 pixel ma il file in formato SVG occupa solo 85 KB. Se poi uno volesse comprimere ulteriormente un’immagine prodotta in grafica vettoriale usando il formato JPEG, per qualche giustificato motivo, non ha che da prendere la versione in PNG, caricarla in Gimp e da lì salvarla in JPEG, con il grado di compressione desiderato. Lo faccio, esagerando, per far vedere ancora il tipo di degenerazione che può venir fuori. Il file in JPEG è diventato di 29 KB ma…
Esempio del modo in cui si deteriora un’immagine prodotto in grafica vettoriale applicandole un’eccessiva compressione JPEG. Qui l’immagine è stato prodotta lavorando con Inkscape sul suo formato nativo SVG, poi è stata esportata nel formato tipo bitmap PNG, che comprime in modo conservativo, quindi è stata caricata in Gimp per essere infine salvata in formato JPEG con qualità del 10%. Clicca l’immagine per vedere bene gli effetti.
Terzo fatto: usare i livelli (layers)
Infine il terzo fatto che fa la differenza in materia di elaborazione di immagini: l’esistenza dei livelli (layers). I livelli consentono di costruire un’immagine attraverso la sovrapposizione di piani contenenti elementi diversi di quella che sarà l’immagine risultante. Un caso tipico può essere quello della sovrapposizione di scritte ad un’immagine fotografica: la fotografia sta in un piano e i testi da sovrapporre stanno in altri piani.
Quello dei livelli è uno strumento potentissimo. Un vantaggio fondamentale è la facilità con cui si può intervenire in tempi successivi solo su alcune parti delle immagini. Cambiare un testo ormai integrato in una fotografia può essere un incubo. Cambiarlo nel suo piano, lasciando tutto il resto inalterato, è un gioco da ragazzi.
Vediamo un esempio costruito sulla solita immagine della locomotiva.
Questa immagine è stata costruita con Gimp in 4 livelli: il primo contiene la fotografia resa monocromatica, il secondo contiene solo il fumo che spiffera dai meccanismi, reso in rosso, il terzo contiene gli elementi grafici in verde e il quarto i testi in giallo.
Le possibilità offerte dai livelli sono sterminate. Per esempio, sempre con Gimp, non è difficile ottenere dalla precedente un’immagina animata in GIF:
Anche il programma in grafica vettoriale Inkscape offre l’elaborazione in livelli. Tuttavia, siccome nella grafica vettoriale ogni oggetto rimane indipendente e può sempre essere riacciuffato successivamente, da solo o in gruppo, i livelli giocano un ruolo un po’ minore, anche se in certe circostanze possono tornare molto utili. Nella grafica bitmap invece l’esistenza dei livelli cambia la vita a chiunque voglia fare qualcosa di appena più elaborato di un semplice ritocco.
Coda
Non ho dato istruzioni per l’uso – come si fa a fare questo o quello. Non credo che si impari per istruzioni preconfenzionate ma per suggestioni. Se la suggestione per qualcuno c’è stata allora costui proverà a fare qualcosa. Se avrà problemi lo scriverà, e noi lo aiuteremo.
Note
B: byte = 8 bit; 1 KB = 1024 B; 1 MB = 1024 KB; quindi 1 MB = 1024 x 1024 B, approssimativamente 1 MB è qualcosa più di un milione di B.
Per chi ha poca dimestichezza con il linguaggio matematico. L’equazione dice molto semplicemente che il risultato dell’operazione a sinistra dell’uguale, deve essere uguale a ciò che c’è alla sua destra, vale a dire uguale a 0. L’operazione a sinistra non è altro che una somma algebrica (vale a dire che c’è anche roba col segno meno) di alcuni termini, che sono a loro volta prodotto di alcuni fattori: x2 vuol dire x moltiplicato x, 2αx vuol dire 2 moltiplicato α moltiplicato x, eccetera. α, β e r sono le cose fisse, i cosiddetti parametri. Sono fisse nel senso che se io attribuisco a ciascuna di esse un valore, allora ho definito una precisa circonferenza, all’interno del mondo di tutte le infinite possibili circonferenze possibili. Rimangono x e y. Queste sono le variabili, quelle che servono a disegnare la circonferenza su un pezzo di carta o sullo schermo del computer, in questo caso. In sintesi, il software considera x e y come le coordinate dei pixel sullo schermo, esattamente come nella battaglia navale o in una carta geografica. Poi si “diverte” a “provare” vari valori della x, risolvendo l’equazione, cioè trovando la y in modo che valga l’uguale. Trovata così la y per ogni x, usa tali valori per individuare il pixel di tali coordinate e lo riempie di colore. Così viene fuori la circonferenza. Questa è una descrizione un po’ semplificata ma è corretta.
Interno cabina della locomotiva a vapore HG 3/4 Nr. 1 “Furkahorn”, fabbricata in Winterthur (CH) nel 1913 per operare sulla tratta a scartamento ridotto di alta montagna Brig-Furka-Disentis, successivamente venduta in Vietnam nel 1947, dove ha lavorato fino al 1993, anno nel quale è stato riportata in Svizzera per viaggiare sulla linea Oberwald-Furka-Realp, da allora operativa nella stagione estiva
I programmi che consentono di salvare immagini nel formato JPEG offrono sempre la possibilità di determinare la qualità regolando il compromesso compressione-qualità mediante un fattore numerico. Talvolta questo fattore è espresso come una percentuale che va da 0 a 100, ma attenzione, questo non rappresenta il fattore di compressione del file risultante ma solo un indice numerico che esprime il livello del suddetto compromesso. Programmi diversi quantificano in maniera diversa tale compromesso, che delle volte è espresso in termini differenti da quello percentuale. Quindi, quando si salva un’immagine in JPEG, dire che si è usato quel certo livello di compressione non vuol dire nulla se non si specifica anche con quale software è stato ottenuto. Ecco perché nel testo abbiamo specificato per esempio “10% secondo Gimp”.
Il diagramma rappresenta un tentativo ingenuo del sottoscritto di descrivere l’attività dell’insegnante nel cMOOC #ltis13 sulla base dell’activity theory di Yrjö Engeström. Giusto per dare un’idea di cosa rappresenti il diagramma, in maniera estremamente sintetica: i triangoli sono una generalizzazione del concetto di azione mediata di Vygotzky, rappresentata con un triangolo che descrive come il soggetto agisca sull’oggetto attraverso una mediazione complessa, realizzata mediante artefatti complessi, strumenti o simboli. Tale generalizzazione prende il nome di activity system e tiene conto del fatto che un soggetto agisce sempre all’interno di un sistema e che la descrizione delle sue azioni rappresentano una particolare prospettiva di quella che in realtà poi risulta un’attività del sistema. Facendo riferimento al triangolo di sinistra, per esempio un insegnante opera in un sistema caratterizzato da precisi insiemi di collaboratori (in basso al centro) che condividono un certo sistema di regole (vertice basso sinistro) e operano secondo una determinata divisione del lavoro (vertice basso destro), producendo, mediante un sistema di strumenti e simboli (vertice alto), un intervento che dovrebbe intercettare le domande e le necessità degli studenti, all’interno dalle loro rispettive zone di sviluppo prossimale.
Stavo scrivendo due post contemporaneamente, ambedue al di fuori del filone HTML. Contemporaneamente, perché non riuscivo a decidermi a quale dare la precedenza, quando è arrivata questa domanda di Roberta:
A proposito di sicurezza di dati…mandare documenti (ad esempio PDF di alunni) in modalità e mail con allegato oppure condividerli con Dropbox o Drive…come funziona…quali sono le modalità più sicure? E’ possibile determinarle?
Come dicevo nella risposta al commento, son mesi che studio, sperimento e annoto per aggiungere un capitolo “sicurezza” nel laboratorio. Ma è un tema vasto e complesso. E poi è necessario calibrare l’intervento sulle necessità più frequenti e cogenti, colmando una distanza fra utenti normali e smanettoni paranoici che da vent’anni è rimasta tale e quale. Colgo quindi la palla al balzo per fare un inciso, poi continueremo con il resto.
Nell’Assignment 6: letteratura scientifica 3 abbiamo fatto delle ricerche in PubMed e abbiamo visto come si puà presentare un articolo in formato testo navigabile, ma ci siamo resi conto che solo di una parte minore degli articoli è disponibile il testo integrale.
Nel video che segue si mostra come appare un articolo scaricato in formato pdf e come si fa ad utilizzare il proxy della rete universitaria in modo da poter accedere anche dall’esterno ai periodici per i quali l’Ateneo ha acquistato l’abbonamento. Guarda il video e trova i link utili …
Credo che sia un libro interessante. Non ho avuto tempo di leggerlo ancora ma mi ha incuriosito questo post dell’autore, Jeff Utecht. Chi ne vuole sapere di più non ha che da scaricare il libro in formato pdf (la password si trova nel post medesimo), entro venerdì intorno alle 22 Pacific Standard Time, quindi intorno alle 7 di sabato mattina.
Nel primo giorno il libro è stato scaricato 803 volte e di questo Jeff si è meravigliato molto, ammettendo che avrebbe già considerato un successo 200 download in totale e che se l’avesse messo in vendita regolarmente si sarebbe ritenuto fortunato vendendone 100 copie. Sempre nella stessa giornata in 15 hanno acquistato il libro.
Vediamo se Jeff ci racconterà quante copie verranno scaricate nei giorni successivi e chissà che non ci ripensi, procrastinando il termine di donwload libero.
Perché, rifacendosi alle considerazioni fatte nel post “Il diritto d’autore: una protezione soffocante” viene spontanea la domanda se per un autore emergente abbia più valore diffondere quasi istantaneamente la propria opera fra un migliaio di persone o venderne, in un periodo decisamente maggiore, un centinaio di copie?
Here you have another assignment for students of the Facoltà di Medicina (INF08) and students of Teorie della comunicazione (TCO08). The attribution for the two groups are just an indication, all of you can choose one of the variants or do both of them.
Students of Teorie della comunicazione (TCO08)
Last monday in classroom we tried to focus on what’s really new in the internet hype. Among other things, we talked about the open source movement and the openness, sharing, peering and global action that characterize the behaviour of an increasing number of companies and organizations in the world. A very important aspect in this context is the evolution of the idea of intellectual property.
Let us try to deepen this idea by reading Bound by Law, a comics created by two lawyers and a cartoonist. It can be downloaded and there is also a template to provide a translation in other languages …
Write your impressions in a post.
Students of the Facoltà di Medicina (INF08)
Well, read the same comics. By the way, you can download it as a pdf file.
Why the pdf exists? Where is it appropriate to use it? Are you already using pdf? In which ways?
Write a post describing one specific feature or use of the pdf format.
Transcribe it in this wiki page. Sign your transcription with a link to your blog post.
Before writing the post go to see in the wiki page what others have written in the meanwhile, so as to avoid duplications.
Use the contents in the wiki as well as any other source in the internet. Quote the sources you used.
Remember that, if they like, INF08 students can do the assignment for TCO08 students and viceversa, or both the assignments.
The second part of the INF08 assignment can be seen as a little experiment about collaborative writing of a sort of manual. The TCO08 students could study it as an online communication experiment …
Last, remember there is a limit for the post length, let us declare it in binaryland language:



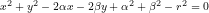






 Credo che sia un libro interessante. Non ho avuto tempo di leggerlo ancora ma mi ha incuriosito
Credo che sia un libro interessante. Non ho avuto tempo di leggerlo ancora ma mi ha incuriosito {kind=link}