Clicca qui per scaricare la versione in pdf (1.8MB)
- Sicuramente un post per gli studenti di “Editing multimediale” della IUL ma anche per tutti quelli a cui capita di lavorare con le immagini
- Grafica bitmap e vettoriale
- Due o tre cose sui formati più noti, GIF, PNG e JPEG, sulla compressione delle informazioni, conservativa e non, e sui formati “dedicati” XCF e SVG
- Gimp e Inkscape, due bellissimi software liberi per l’elaborazione delle immagini che girano su Linux, Mac e Windows
- Elaborazione delle immagini in livelli
Primo fatto: software libero anziché proprietario
Il fatto che il software sia libero o proprietario è fondamentale, per motivi etici prima ancora che tecnici. L’espressione sintetica di Marina è perfetta:
software libero vuol dire che rende le persone più libere
Aggiungo: la scuola e l’università hanno il dovere morale di dimostrare, diffondere e promuovere il software libero. Il resto l’abbiamo detto in un post precedente.
Secondo fatto: distinguere fra grafica bitmap e vettoriale
Immagini digitali
Le immagini digitali sono sempre formate da una sorta di scacchiera di piccoli quadratini denominati pixel, il cui interno è rappresentato con un colore uniforme al quale nel computer corrisponde un certo valore numerico. Anche se le immagini sono monocromatiche vale lo stesso concetto. Per fare un esempio noto a tutti, le immagini TAC (Tomografia Assiale Computerizzata) sono rappresentate in scale di grigi. Ebbene, anche lì in ogni pixel, l’intensità di grigio è in relazione con un numero che rappresenta (con una certa approssimazione) la densità media dei tessuti del corpo nella spazio rappresentato da quel pixel.
dpi e risoluzione
In qualsiasi immagine digitale potete scorgere i pixel, se vi avvicinate o la ingrandite a sufficienza. Naturalmente è proprio quello che non si vuole vedere, di solito. In questo articolo useremo il termine risoluzione per il numero di pixel dell’immagine – maggiore risoluzione significa maggior numero di pixel. In realtà, il concetto di risoluzione spaziale di un’immagine è differente e molto più complesso ma qui ci atterremo alla prassi corrente per rendere il discorso più agile e compatto. Invece con dimensione intenderemo la grandezza del file in cui l’immagine viene memorizzata, e potrà essere espressa in Mega Byte (MB) o in Kilo Byte (KB) [1].Per esempio se fate una scansione di un documento o un’immagine dovete fare attenzione al parametro dpi (dots per inch, punti per pollice). Un pollice sono 2.54 cm e valori accettabili stanno usualmente fra 100 e 200 dpi, ma dipende da cosa dovete scannerizzare. Occorre quindi fare delle prove scegliendo il valore più basso che dà la qualità adeguata, nel contesto che vi interessa. Non vale esagerare, perché la dimensione delle immagini cresce grandemente in proporzione inversa alle dimensioni dei pixel: se i pixel di un’immagine sono più piccoli vuol dire che ve ne saranno di più – se scelgo 200 dpi anziché 100, vuol dire che su ogni lato dell’immagine ho il doppio dei pixel, quindi il numero totale dei pixel dell’immagine sarà 2×2=4 volte più grande, ergo raddoppiare la dimensione lineare vuol dire quadruplicare la dimensione dell’immagine, e quindi anche la dimensione del file dove questa viene memorizzata. Infatti, dal punto di vista del computer, un’immagine digitale è semplicemente una fila di numeri, tanti quanti sono i pixel in cui è suddivisa. Quando il computer la deve rappresentare su un qualche supporto – monitor, stampa… – allora legge i numeri a partire dal primo e decodifica ciascuno di essi in maniera da produrre l’effetto dovuto, in termini di colore e intensità, poi li “scrive” nello spazio dell’immagine come si fa nelle lingue occidentali: da sinistra a destra, dall’alto al basso.
Tipi di grafica
Ma non sempre le immagini vengono memorizzate secondo la logica di un “elenco dei contenuti dei pixel”. Si danno infatti due possibilità, una che prende il nome di grafica vettoriale e l’altra di grafica bitmap, o grafica raster (raster: griglia; da qui in poi utilizzeremo il termine bitmap). Le immagini bitmap sono memorizzate così come abbiamo già detto. Ad esempio le fotografie e le immagini mediche sono di questo tipo. Le immagini vettoriali sono invece memorizzate attraverso una rappresentazione ad oggetti. I disegni CAD (Computer Assisted Design) fatti da un progettista e i documenti PDF sono esempi di immagini vettoriali. Facciamo un esempio affinché la differenza sia chiara.
Grafica bitmap
Supponiamo prima di disegnare una circonferenza con un software di tipo bitmap, poi immaginiamo di ingrandire molto l’immagine: prima o poi la circonferenza rivelerà la struttura in pixel, che le darà un aspetto frastagliato.

Grafica vettoriale
Disegnate ora la stessa circonferenza con un software di tipo vettoriale e provate a ingrandire l’immagine a piacimento: la circonferenza sarà sempre lì, con gli stessi identici attributi che le avrete assegnato all’atto della sua creazione. Magari ne vedete solo un piccolo arco perché avete ingrandito l’immagine veramente tanto, ma non vi sono artefatti.

Perché questa differenza? Il software di tipo bitmap parte da un’immagine che è tanti pixel alta e tanti pixel larga. Dopodiché qualsiasi cosa facciate, il software si preoccupa di riempire i pixel come dite voi. Altro non fa. Se avete chiesto di disegnare una circonferenza, il sistema utilizza l’equazione matematica della circonferenza
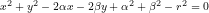
dove α e β sono le coordinate del centro e r è il raggio della circonferenza, per riempire appropriatamente i pixel. Poi se ne dimentica, ovvero dimentica i suoi parametri, α, β e r [2]. Invece, il software di tipo vettoriale, utilizza l’equazione della circonferenza per disegnarla sullo schermo, con i parametri di rappresentazione correnti, ovvero riempie i pixel che voi vedete sullo schermo, e invece di memorizzarne i contenuti memorizza l’equazione della circonferenza, sotto forma dei suoi parametri α, β e r, e di altri eventuali attributi grafici, quali spessore e colore della linea. Poi, ogni volta che voi rinfrescate l’immagine sullo schermo, ricaricandola o variandone le dimensioni, ricalcola i contenuti dei pixel a partire dall’equazione della circonferenza. E così per tutti gli altri oggetti.
Riassumendo, con la grafica bitmap il sistema ricorda i contenuti di tutti i pixel dell’immagine – quando la deve rappresentare sul schermo costruisce l’immagine semplicemente rappresentando adeguatamente i singoli pixel. Con la grafica vettoriale il sistema ricorda l’idea di circonferenza, ovvero di quella precisa circonferenza con il centro posizionato in quella certa posizione, con quel certo raggio, con quel certo spessore e quel certo colore con cui deve essere tracciata – quando deve rappresentare l’immagine, prima calcola i contenuti dei pixel per rappresentare quella circonferenza, poi rappresenta i pixel così calcolati sullo scheermo.
Formati – compressione
Non vogliamo perderci qui nella foresta dei formati. Se necessario approndiremo dove opportuno. Solo gli esempi comuni. Tutte le immagini di origine fotografica sono gestite e memorizzate con la logica bitmap. È naturale: derivano tutte da una qualche matrice di rivelatori, intendendo per matrice una qualche precisa disposizione di rivelatori di radiazione elettromagnetica: luminosa, infrarossa, X o altro. I formati più comuni per la distribuzione di immagini bitmap nel web sono GIF, PNG e JPEG – detto anche JPG, è lo stesso.
Qui occorre un inciso sulla compressione. Le immagini – anche l’audio e a maggior ragione il video – contengono molta informazione, quindi i file tendono ad essere grandi – oggi si ama dire che sono “pesi”. Persino la fotocamera di un telefono produce immagini di vari milioni di pixel. Far viaggiare questa roba in internet può essere un problema, a maggior ragione per chi vive in paesi sottosviluppati – o “diversamente sviluppati”, come il nostro, duole dirlo ma all’atto pratico, fra la velocità di trasferimento subalpina e quella sovralpina può corre tranquillamente un fattore 10. Le tecniche di compressione dell’informazione sono quindi fondamentali, è grazie a queste che la distribuzione dell’informazione multimediale è esplosa, ad esempio nei formati MP3 (audio), JPEG (immagini) e MP4 (video). Tutti questi esempi – sono i più comuni ma ve ne sono tanti altri – sono caratterizzati dal fatto di impiegare un qualche sistema di compressione dell’informazione. E tutti e tre usano i sistemi di compressione più efficaci, ovvero quelli non conservativi, che per comprimere meglio buttano via qualcosa – qualcosa che non si sente nell’audio, che non si vede nelle immagini o nei video. Sono sistemi regolabili – se si esagera si finisce col deteriorare il messaggio.
Con la compressione conservativa invece non si butta via nulla, ma si sfruttano ripetizioni e regolarità, sfruttandole in modo intelligente. Ci capiamo subito con questo esempio: pensate a un’immagine fatta da un solo pixel centrale nero e tutti gli altri bianchi – non è interessante ma è utile per capire. Non è difficile immaginare un sistema abbastanza furbo da memorizzare il numero di pixel che sono uguali e il loro (unico) valore. Nel nostro esempio significa che invece di memorizzare milioni di numeri, basta memorizzare il numero dei pixel bianchi, il numero di quelli neri e i due valori corrispondenti al bianco e al nero: 4 numeri! Abbiamo semplificato molto ma il concetto c’è, ed è anche sufficiente a capire che il successo di questi metodi dipende dal tipo di immagine. Per esempio in un’immagine fotografica piena di sfumature morbide ci sarà poco da comprimere. Un esempio di compressione conservativa molto noto è quello del formato ZIP. Può valer la pena di fare un giochino. Prendo un brano di questo scritto, lo salvo in un file con un editore di testo – un editore di testo, non Word! – Mi è venuto un file di 1075 byte. Sempre con l’editore di testo scrivo “pippo pippo…” tante volte (alla Shining – non mi sta vedendo nessuno…) fino a ottenere un file egualmente lungo, ovvero di 1075 byte. Applico a tutti e due lo zip: nel primo caso viene un file di 725 byte e nel secondo di 173 byte. Potete provare anche voi per esercizio, inventandovi degli esempi simili, o scaricando il file numero 1 e il file numero 2 per zipparli da voi.
Dunque dicevamo che i formati più comuni per la distribuzione di immagini bitmap nel web sono, GIF, PNG e JPEG. Vediamoli brevemente.
Il formato GIF usa una compressione conservativa. Questo lo rende adatto a immagini che contengono testo o grafica composta da linee. Si può usare per fare immagini animate.
Anche il formato PNG comprime l’immagine in modo conservativo e quindi anche questo è adatto nei casi cui sono presenti testo o linee. È meglio rispetto al GIF perché è più recente: consente di rappresentare le immagini con maggiore qualità e le comprime meglio. Non si possono però fare immagini animate, per questo ci vuole il formato GIF. In fondo vedremo un esempio.
Il formato JPEG applica invece una compressione non conservativa. È il formato adatto alle immagini fotografiche. Se siamo noi a generare un file JPEG, allora all’atto del salvataggio si può scegliere il grado di compressione. Occorre controllare quindi: più si comprime e più l’immagine può risultare degradata, specialmente se vi sono dettagli fini e contrasti bruschi.
Per quanto riguarda la grafica vettoriale occorre certamente citare il PDF. È un’ottima occasione per puntualizzare che il PDF è un formato grafico, e per di più vettoriale, perché molti scambiano il PDF per una variante del formato DOC – quello di Word, o altri word processor. No, il PDF non è un formato di testo o testo formattato, bensì è un formato grafico: esportare un documento qualsiasi – testo, foglio di lavoro o altro – in PDF vuole dire farne una sorta di fotografia, ovvero congelarlo in un’immagine, e per di più un’immagine vettoriale, perché così risulta meno sensibile alla modalità con la quale viene rappresentato, grazie al meccanismo ad oggetti che abbiamo visto. Perché il PDF è nato proprio per diffondere documenti nella rete, in maniera che questi rimangano inalterati, indipendente dal supporto di visualizzazione o dalla modalità di stampa.
Manipolando foto
La questione del formato è particolarmente importante quando siamo noi che creiamo le immagini. Le immagini si possono presentare in una grande varietà di forme, agli estremi abbiamo le fotografie da un lato e i “disegni al tratto” dall’altro – diagrammi, grafici. Di foto ne produciamo tutti tante, anche troppe. La tendenza è scattare e riempire memorie – pensa a tutto la macchina. In realtà anche in un cellulare di fascia bassa si può intervenire su alcuni parametri, per non parlare degli smartphone. Sicuramente si possono determinare numero di pixel e qualità dell’immagine. La dimensione dei file cresce con il numero dei pixel e la qualità dell’immagine. La qualità è di fatto regolata mediante il rapporto di compressione JPEG. Prima di usare l’apparecchio, non sarebbe male fare delle prove, ripetendo lo stesso scatto con risoluzioni e qualità diverse, per poi scegliere i parametri che consentono di ridurre le dimensioni dei file ma senza introdurre artefatti nell’immagine.
Chi ha qualche velleità fotografica e utilizza macchine “serie” – reflex, street photography, grandi formati – ha certamente a disposizione l’opzione del formato cosiddetto RAW – raw data: dati grezzi. Questi sono i numeri letti direttamente dai sensori dell’apparecchio, sui quali si può lavorare successivamente con gli appositi software di elaborazione fotografica. È il formato prediletto da chi vuol partecipare alla costruzione dell’immagine fotografica, un po’ come coloro che amavano sviluppare le proprie foto nella camera oscura. Con il formato RAW la libertà di espressione è maggiore ma anche la dimensione dei file è molto più grande dei file JPEG – meno scatti, più riflessione post processing – ex camera oscura – più qualità.
Fabbricando immagini
Diverso è il caso in cui le immagini ce le dobbiamo fabbricare “a mano”. Qui la risposta non è univoca perché dipende da quello che si deve fare. Nel caso di diagrammi o grafici, quasi certamente conviene optare per un formato di tipo vettoriale. Costruendo invece immagini composite nelle quali gli elementi fotografici sono importanti, allora probabilmente si può lavorare sia in forma vettoriale che bitmap – la scelta dipende dal tipo di fruizione dei risultati e, in ultima istanza, dalle preferenze personali.
Lavorare in forma grafica bitmap o vettoriale vuol dire usare software diversi. Qui citiamo due ottimi software liberi: Gimp per la grafica bitmap e Inkscape per la grafica vettoriale. La quantità e varietà di software e di servizi web per l’elaborazione delle immagini è impressionante. Molti conosceranno Photoshop per il ritocco delle immagini fotografiche, e forse avranno sentito nominare Autocad per la progettazione, quali esempi di software per grafica bitmap da un lato e vettoriale dall’altro, anche se quest’ultimo più di nicchia e strettamente professionale. Sono programmi dal prezzo elevato, probabilmente ingiustificato per la maggioranza delle finalità che può avere un utente generico. In realtà le alternative libere Gimp e Inkscape sono molto sofisticate e possono essere usate con profitto anche in contesti professionali. Gli esempi precedenti, dove abbiamo mostrato cosa succede ingrandendo immagini dei due tipi sono stati realizzati con questi due software, ma vediamo qualche esempio per dare un’idea delle potenzialità e delle differenze fra le due modalità.
Lavorare in grafica bitmap con Gimp

Questa immagine – chi vuole sapere di che si tratta può leggere la nota [3] – è stata è stata scattata con un apparecchio comune, di quelli automatici, nemmeno più tanto recente, e ciò nonostante già in grado di sparare immagini di 4320×3240 pixel, come questa che vedete qui sopra, espressa in tre diversi formati, da sinistra a destra: PNG – compressione conservativa, cioè nessun degrado ma il file occupa 19MB; JPEG con compressione ridotta (94
Ma la differenza c’è, dipende da come si intende usare l’immagine, in particolare da quanto si pensa di ingrandirla. Le tre immagini sopra sono scalate per farle entrare nel post, cliccando sopra appaiono le versioni originali, sulle quali potete cliccare un’altra volta per ingrandirle ulteriormente. Se con il vostro browser non funziona così, potete scaricarle sul vostro computer e poi ingrandirle con il software di visualizzazione di immagini che usate di solito. Ebbene, vedrete che, ingrandendo molto, se fra le versioni PNG (a sinistra) e JPEG 94
Ma vediamo ancora più in dettaglio come stanno le cose, confrontando un particolare dell’immagine senza alterazioni, con risoluzione ridotta, con compressione JPEG e con tutti e due i trattamenti.

Per vedere bene gli effetti occorre cliccare sull’immagine qui sopra, che è scalata per farla entrare nell’impaginazione, e poi cliccare nuovamente sull’immagine che appare per ingrandirla ulteriormente.
Ebbene, se la dimensione del file dell’immagine originale era di 19 MB, sia riducendo la risoluzione del 20
Quindi, primo messaggio: per ridurre il “peso” di un’immagine si può agire sul parametro di qualità-compressione del formato JPEG ma occhio alla risoluzione: se i pixel sono pochi il rischio di rovinare l’immagine è alto, quindi bisogna essere prudenti: andare per tentativi e errori.
Secondo messaggio: per lavorare bene, può avere senso porsi il problema se convenga ridurre le dimensioni riducendo la risoluzione oppure comprimendo di più con il JPEG. Si confrontino le immagini 2), compressa con JPEG, e 3), alleggerita riducendo la risoluzione. La prima ha i contorni più conservati mentre si sono praticamente perse le sfumature delle superfici piane. Nella seconda le sfumature delle superfici sono ancora ben rappresentate ma i contorni sono deteriorati dalla dimensione dei pixel – meno pixel vuol dire pixel più grossi. Da tutto questo si vede come in ambedue i casi la riduzione delle dimensioni dell’immagine sia stata ottenuta al prezzo della perdita di una certa quantità di informazione, ma che tale perdita è qualitativamente diversa nei due casi. La riduzione della risoluzione tende a sciupare i contorni, la compressione JPEG tende a sparpagliare la degenerazione nell’immagine. L’indicazione pratica che se ne ricava è che nel caso di immagini morbide e con poche variazioni brusche di contrasto conviene ridurre la risoluzione, ovvero il numero di pixel; invece nel caso di immagini dove predominano linee e contorni forti, può convenire ricorrere ad una compressione JPEG più energica. In ogni caso: domandarsi come verrà usata l’immagine e cosa vogliamo comunicare e poi andare per tentativi ed errori, perché gli effetti cambiano a seconda del tipo di immagine.
Chi si cimenta nell’uso di Gimp si accorge che fra i 40 formati nei quali può salvare un’immagine, il primo che viene proposto è XCF. Questo è il formato nativo di Gimp, ovvero quello che è in grado di memorizzare tutte le informazioni fra una sessione di lavoro e l’altra. È il formato da usare quando si lavora con un’immagine e la vogliamo mantenere per ritornarci a lavorare in futuro – se la memorizziamo in questo formato siamo sicuri di ritrovare tutta quello che abbiamo fatto in precedenza. Non è il formato da usare per inviare un’immagine in rete, a meno che uno non voglia condividerla con qualcun altro che debba continuare a lavorarci con Gimp. Il processo corretto quindi è quello di memorizzare tutte le varie versioni dello sviluppo in XCF e poi esportare il risultato in un formato idoneo a essere trasmesso, per esempio GIF, PNG, JPEG o altro.
Resterebbe da dire qualcosa sulle elaborazioni in grafica bitmap, ma vedremo meglio dopo, ragionando del terzo fatto che fa la differenza, in materia di manipolazione di immagini.
Lavorare in grafica vettoriale con Inkscape
Le immagini si possono creare anche in grafica vettoriale. Anche per questo tipo di elaborazione esiste uno splendido software libero, che è Inkscape. Vediamo un esempio.
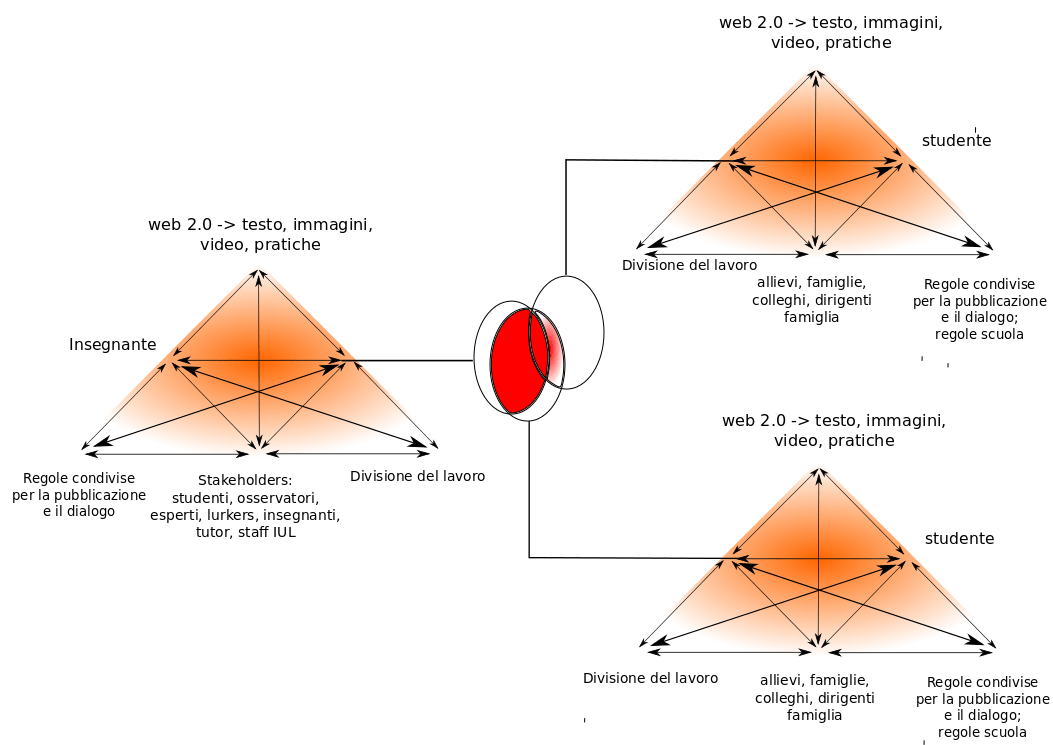
Il soggetto dell’immagine non ci interessa qui, se non per come è stato costruito graficamente. Chi fosse incuriosito dal senso del diagramma può leggere una breve nota [5]. Come abbiamo già visto, nella modalità vettoriale, ad essere memorizzati non sono i pixel dell’immagine ma le caratteristiche geometriche degli oggetti – in questo caso triangoli, ellissi, segmenti di vario tipo, sfondi, testi. È una modalità comodissima per fabbricare un diagramma del genere. Una volta costruito un triangolo, con le sue frecce, il suo sfondo e i testi, per fare gli altri, basta raggruppare tutti gli elementi con una semplice riquadratura e duplicare il tutto, spostare la copia nella posizione desiderata e poi intervenire sui singoli elementi che debbano essere eventualmente cambiati, per esempio i testi in questo caso. Ciò è reso possibile dal fatto che il sistema tiene traccia di ogni singolo oggetto e di ogni sua caratteristica, in un modo che rende molto semplice manipolarlo, riprodurlo e nuovamente alterarlo in ogni successiva fase del lavoro:
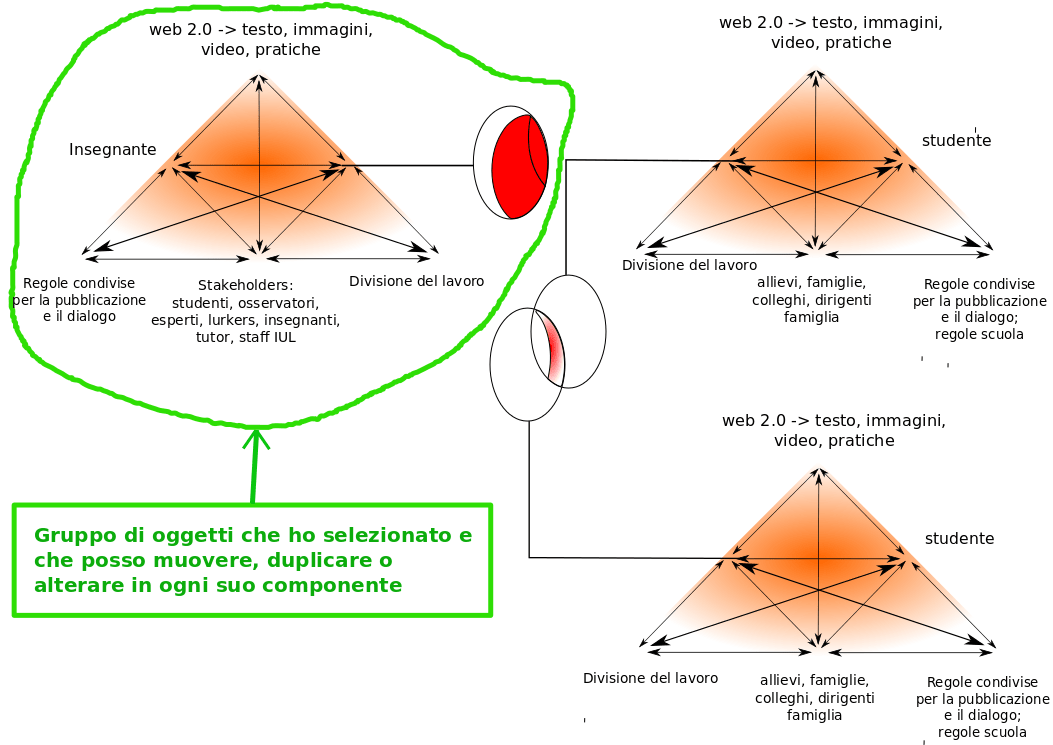
Fra i casi estremi che abbiamo mostrato esiste tutta una zona intermedia di risultati che possono essere raggiunti con ambedue i sistemi. Per averne un’idea può essere interessante andare a vedere in DeviantART – un social network dedicato alle creazione grafiche – i lavori fatti sia dagli appassionati di Gimp che da quelli di Inkscape.
Anche Inkscape ha un formato di riferimento che conserva tutto ciò che serve per conservare il lavoro fra sessioni successive, è lo SVG. Valgono le stesse considerazioni fatte a proposito del formato XCF di Gimp. La differenza con Gimp è che Inkscape non offre formati che comprimono in modo non conservativo – per esempio si può salvare in PNG ma non in JPEG. Del resto, se vogliamo, il formato vettoriale opera intrinsecamente una forma di compressione, memorizzando solo i parametri geometrici degli elementi presenti anziché i contenuti dei pixel, che sono quasi sempre centinaia di migliaia o milioni. Ad esempio, l’immagine precedente, che è anche abbastanza complessa, è composta da 780’000 pixel ma il file in formato SVG occupa solo 85 KB. Se poi uno volesse comprimere ulteriormente un’immagine prodotta in grafica vettoriale usando il formato JPEG, per qualche giustificato motivo, non ha che da prendere la versione in PNG, caricarla in Gimp e da lì salvarla in JPEG, con il grado di compressione desiderato. Lo faccio, esagerando, per far vedere ancora il tipo di degenerazione che può venir fuori. Il file in JPEG è diventato di 29 KB ma…

Terzo fatto: usare i livelli (layers)
Infine il terzo fatto che fa la differenza in materia di elaborazione di immagini: l’esistenza dei livelli (layers). I livelli consentono di costruire un’immagine attraverso la sovrapposizione di piani contenenti elementi diversi di quella che sarà l’immagine risultante. Un caso tipico può essere quello della sovrapposizione di scritte ad un’immagine fotografica: la fotografia sta in un piano e i testi da sovrapporre stanno in altri piani.
Quello dei livelli è uno strumento potentissimo. Un vantaggio fondamentale è la facilità con cui si può intervenire in tempi successivi solo su alcune parti delle immagini. Cambiare un testo ormai integrato in una fotografia può essere un incubo. Cambiarlo nel suo piano, lasciando tutto il resto inalterato, è un gioco da ragazzi.
Vediamo un esempio costruito sulla solita immagine della locomotiva.

Le possibilità offerte dai livelli sono sterminate. Per esempio, sempre con Gimp, non è difficile ottenere dalla precedente un’immagina animata in GIF:

Anche il programma in grafica vettoriale Inkscape offre l’elaborazione in livelli. Tuttavia, siccome nella grafica vettoriale ogni oggetto rimane indipendente e può sempre essere riacciuffato successivamente, da solo o in gruppo, i livelli giocano un ruolo un po’ minore, anche se in certe circostanze possono tornare molto utili. Nella grafica bitmap invece l’esistenza dei livelli cambia la vita a chiunque voglia fare qualcosa di appena più elaborato di un semplice ritocco.
Coda
Non ho dato istruzioni per l’uso – come si fa a fare questo o quello. Non credo che si impari per istruzioni preconfenzionate ma per suggestioni. Se la suggestione per qualcuno c’è stata allora costui proverà a fare qualcosa. Se avrà problemi lo scriverà, e noi lo aiuteremo.
Note
- B: byte = 8 bit; 1 KB = 1024 B; 1 MB = 1024 KB; quindi 1 MB = 1024 x 1024 B, approssimativamente 1 MB è qualcosa più di un milione di B.
- Per chi ha poca dimestichezza con il linguaggio matematico. L’equazione dice molto semplicemente che il risultato dell’operazione a sinistra dell’uguale, deve essere uguale a ciò che c’è alla sua destra, vale a dire uguale a 0. L’operazione a sinistra non è altro che una somma algebrica (vale a dire che c’è anche roba col segno meno) di alcuni termini, che sono a loro volta prodotto di alcuni fattori: x2 vuol dire x moltiplicato x, 2αx vuol dire 2 moltiplicato α moltiplicato x, eccetera. α, β e r sono le cose fisse, i cosiddetti parametri. Sono fisse nel senso che se io attribuisco a ciascuna di esse un valore, allora ho definito una precisa circonferenza, all’interno del mondo di tutte le infinite possibili circonferenze possibili. Rimangono x e y. Queste sono le variabili, quelle che servono a disegnare la circonferenza su un pezzo di carta o sullo schermo del computer, in questo caso. In sintesi, il software considera x e y come le coordinate dei pixel sullo schermo, esattamente come nella battaglia navale o in una carta geografica. Poi si “diverte” a “provare” vari valori della x, risolvendo l’equazione, cioè trovando la y in modo che valga l’uguale. Trovata così la y per ogni x, usa tali valori per individuare il pixel di tali coordinate e lo riempie di colore. Così viene fuori la circonferenza. Questa è una descrizione un po’ semplificata ma è corretta.
- Interno cabina della locomotiva a vapore HG 3/4 Nr. 1 “Furkahorn”, fabbricata in Winterthur (CH) nel 1913 per operare sulla tratta a scartamento ridotto di alta montagna Brig-Furka-Disentis, successivamente venduta in Vietnam nel 1947, dove ha lavorato fino al 1993, anno nel quale è stato riportata in Svizzera per viaggiare sulla linea Oberwald-Furka-Realp, da allora operativa nella stagione estiva
- I programmi che consentono di salvare immagini nel formato JPEG offrono sempre la possibilità di determinare la qualità regolando il compromesso compressione-qualità mediante un fattore numerico. Talvolta questo fattore è espresso come una percentuale che va da 0 a 100, ma attenzione, questo non rappresenta il fattore di compressione del file risultante ma solo un indice numerico che esprime il livello del suddetto compromesso. Programmi diversi quantificano in maniera diversa tale compromesso, che delle volte è espresso in termini differenti da quello percentuale. Quindi, quando si salva un’immagine in JPEG, dire che si è usato quel certo livello di compressione non vuol dire nulla se non si specifica anche con quale software è stato ottenuto. Ecco perché nel testo abbiamo specificato per esempio “10
- Il diagramma rappresenta un tentativo ingenuo del sottoscritto di descrivere l’attività dell’insegnante nel cMOOC #ltis13 sulla base dell’activity theory di Yrjö Engeström. Giusto per dare un’idea di cosa rappresenti il diagramma, in maniera estremamente sintetica: i triangoli sono una generalizzazione del concetto di azione mediata di Vygotzky, rappresentata con un triangolo che descrive come il soggetto agisca sull’oggetto attraverso una mediazione complessa, realizzata mediante artefatti complessi, strumenti o simboli. Tale generalizzazione prende il nome di activity system e tiene conto del fatto che un soggetto agisce sempre all’interno di un sistema e che la descrizione delle sue azioni rappresentano una particolare prospettiva di quella che in realtà poi risulta un’attività del sistema. Facendo riferimento al triangolo di sinistra, per esempio un insegnante opera in un sistema caratterizzato da precisi insiemi di collaboratori (in basso al centro) che condividono un certo sistema di regole (vertice basso sinistro) e operano secondo una determinata divisione del lavoro (vertice basso destro), producendo, mediante un sistema di strumenti e simboli (vertice alto), un intervento che dovrebbe intercettare le domande e le necessità degli studenti, all’interno dalle loro rispettive zone di sviluppo prossimale.
Molto interessante,lo riascolterò ancora per capire meglio,molte grazie.
Ho un “problema” con lo zippaggio (o zippamento?).
Ho copiato i due testi in text edit, l’editore di testo del Mac.
Entrambi i documenti mi risultano di 1 Kb. Il numero dei byte non cambia zippando il documento che contiene il brano, mentre quello con “pippo” mi risulta compresso, ma non tanto come viene ad Andreas. Il mio risulta essere di 729 byte.
Come mai?
Grazie per le delucidazioni.
Ma TextEdit l’hai usato in modo “testo”? Perché lui è un editore ibrido, che di default produce file in formato rtf. Se li vuoi in formato testo allora glielo devi dire, in uno dei suoi menu. Domattina potrò controllare su un Mac, ora non ne ho uno a disposizione. Se lo salvi in formato rtf ci salva altra roba e questo certamente impedisce allo zip di sfruttare la regolarità del testo “pipppo pippo…”
Eh, già! Che furba! L’avevo salvato in .rtf.
L’ho rifatto in “solo testo” e queste sono le dimensioni dei file. Nel brano contenente parole disparate non c’è differenza, che invece è sostenuta nel file dove viene ripetuta sempre la stessa parola.
pippo.txt 1 Kb
pippo.txt.zip 597 byte
zippare.txt 1 Kb
zippare.txt.zip 1 Kb
Grazie
Ottimo 🙂
Mi sto dilettando ad aggeggiare immagini con Gimp anche se con molta fatica. Da qualche ora sono impallata con un problema: quando provo a fare l’esecuzione di un movimento o comunque di un’animazione la finestra che mi appare è enorme così che io posso vedere solo un angolo dell’inquadratura e non controllo ad esempio il movimento di una parte…credo di aver provato ispezionando tutte impostazioni ma non ho attenuto risultati. Qualcuno ha la soluzione? Grazie
Mmmh, difficile questo da risolvere a distanza. Può dipendere da un sacco di cose. In casi del genere, cioè quando vengono aperte finestre che debordano, per andare a cercare un angolino da acciuffare per ridimensionarle, le sposto trascinando con il mouse ma tenendo premuto contemporaneamente il tasto Alt e il tasto sinistro del mouse. Questo con Ubuntu (e Gnome). Non so se funziona così con altri sistemi. E non so nemmeno se è una cosa che serve in codesto caso, che si giudica poco e nulla senza vedere…
Diciamo che andando per prove ed errori ho maturato un dubbio che proverò a verificare nei prossimi giorni…comincio a pensare che dipenda dalla “pesantezza” dell’immagine su cui si lavora. Infatti accade solo con foto di un certo “volume” pur avendole ridotte come dimensioni (ho selezionato parte di foto) mentre non avviene con le immagini di disegni…tutte le opzioni di trascinamento e/o rimpicciolimento che conosco le ho provate ma non mi hanno dato risultati. Vi terrò aggiornati…grazie comunque! A presto
Brava! Ottima ipotesi. Prova, appena caricata l’immagine in Gimp, a scalarla subito con Immagine->Scala immagine (credo, ho la versione inglese qui).
Ottimo! I passaggi sono stati: caricare l’immagine, scalarla ai minimi termini, visulalizzarla con uno zoom decente altrimenti sarebbe stato impossibile selezionare qualsiasi parte, quindi aggeggiare a piacere e poter vedere l’anteprima dell’esecuzione con gran soddisfazione!!! Grazie mille…adesso posso andare a lavoro serena. Buona giornata.
Bene, sono proprio contento 🙂
Questo argomento mi intriga moltissimo, perchè ci vedo un collegamento con la problematica della digitalizzazione delle immagini storiche fotografiche che si sta affrontando nella studio della storia dei processi formativi in questo semestre alla IUL, per quanto concerne la riproduttività dell’originale, la sua catalogazione: ciò che si perde e ciò che resta durante questo processo, come ciò è utilizzabile in una ricerca storiografica al di là dell’uso “classico”…grazie prof. ci farò qualche ragionamento!!!!
È molto interessante che la IUL tratti anche questi aspetti invece di darli come scontati, in un corso del genere.
Per coincidenza, questo mese, Hartwig Thomas ha condiviso un saggio che sta scrivendo sulla conservazione digitale a lungo termine delle opere nella mailing list di Digitale Allmend, l’associazione che, tra altre cose, gestisce le versioni adattate al diritto svizzero delle licenze creative commons.
La mailing list è privata ma il saggio – ancora in fieri – è sotto licenza CC “Attribuzione – Condividi allo stesso modo”. Allora l’ho aggiunto per scaricamento nel wiki di #loptis: vedi qui.
Grazie per questo link Claude. È lodevole la missione di Pro Cultura Libera – i motivi non possono che essere condivisibili. Tuttavia, mentre sono completamente d’accordo nell’enfasi su formati e strumenti aperti e standard, ho qualche dubbio sull’utilità di un repository. Essendo anche elvetico, oltre che italiano, conosco perfettamente l’anelito alla stabilità e alla sicurezza che caratterizza quel popolo, ma credo che il turbine evolutivo di questa fase storica – attimo – imponga una rivisitazione di tali aneliti. Bada bene, sicuro che mi piacerebbe potesse esistere un repositorio durevole di ciò che ha valore. Quello che temo è che sia semplicemente impossibile realizzarlo.
Sì, è molto interessante il nesso che proponi. Facci sapere 🙂
Reblogged this on Il Blog di Tino Soudaz 2.0 ( un pochino).
Grazie infinite…tutte informazioni utilissime soprattutto per chi come me lavora molto con le immagini, nella costruzione di attività didattiche per i bambini… Ho imparato comunque a utilizzare paint per modificare e ridurre e lavorare sulle immagini per evitare formati molto pesanti… Soprattutto per chi ha il problema come me di computer assai obsoleti a scuola!!… Grazie al prof e a tutti gli altri per i consigli!!.. Ciao
Non mi è stato facile leggere/capire/comprendere questo post, sono sincera.
Il mondo delle immagini è per me quasi inconosciuto, ma questo mi stimola a cercare di capire qualcosa. Grazie per le spiegazioni dettagliate e le applicazioni!
Ho letto anche i commenti… anche io sono rimasta perplessa in merito alla definizione di PDF. Per quanto riguarda invece Photoshop e Autocad effettivamente mi sono sempre posta il problema del costo e ora trovo utile e molto formativo sapere che esistono delle valide alternative ‘libere’.
Devo leggere e rileggere ancora, o forse decidermi a sperimentare?!
Grazie 😉
giocare giocare giocare
Ho riletto le istruzioni di Claude e con calma, dopo due giorni di febbre…mi sono rimessa alla prova, non è un grande prodotto lo so, ma intanto ho scoperto che il livello con “trasparenza” non è facilmente esportabile, perciò ho provato un’altra possibilità.
Ora vorrei provare a mettere un testo su questo livello…
Una prova alla volta…
Giusi
Ho provato ad usare GIMP, sarebbe meglio dire che ho provato a giocarci, cercando intuitivamente di capire, ma come ho scritto nel blog, quella “manipolazione” dell’immagine che nel programma vedo e che risulta salvata non riesco a caricarla nel blog.
Per ora mi arrendo, ma riproverò!
Giusi
Premetto: non ho nemmeno scaricato GIMP perché sono più portata per l’audio che per le immagini. Però appunto, per analogia con Audacity che uso per modificare file audio, forse la soluzione al tuo problema sta nel passo:
“Chi si cimenta nell’uso di Gimp si accorge che fra i 40 formati nei quali può salvare un’immagine, il primo che viene proposto è XCF. Questo è il formato nativo di Gimp, ovvero quello che è in grado di memorizzare tutte le informazioni fra una sessione di lavoro e l’altra. È il formato da usare quando si lavora con un’immagine e la vogliamo mantenere per ritornarci a lavorare in futuro – se la memorizziamo in questo formato siamo sicuri di ritrovare tutta quello che abbiamo fatto in precedenza. Non è il formato da usare per inviare un’immagine in rete, a meno che uno non voglia condividerla con qualcun altro che debba continuare a lavorarci con Gimp. Il processo corretto quindi è quello di memorizzare tutte le varie versioni dello sviluppo in XCF e poi esportare il risultato in un formato idoneo a essere trasmesso, per esempio GIF, PNG, JPEG o altro.”
del post di Andreas, sopra. Tu hai salvato semplicemente come XCF, o hai anche esportato in uno di quei “formati idonei” che menziona??
Ecco, tra le domande che annunciavo in un altro commento, ce ne sarebbero delle interessanti, tipo se i filtri dell’elaborazione dell’immagie (e del suono), o se le annotazioni aggiunte su una cattura di schermo, creano livelli (layers).
Ma purtroppo mi sta bloccando il non capire quel che hai scritto sui PDF:
“Per quanto riguarda la grafica vettoriale occorre certamente citare il PDF. È un’ottima occasione per puntualizzare che il PDF è un formato grafico, e per di più vettoriale, perché molti scambiano il PDF per una variante del formato DOC – quello di Word, o altri word processor. No, il PDF non è un formato di testo o testo formattato, bensì è un formato grafico”
Ora, questa frase l’ho selezionata, copiata e incollata qui dal PDF linkato in “Clicca qui per scaricare la versione in pdf (1.8MB)” in cima a questo post. E manco c’erano degli a-capo forzati a fine riga. Se quel PDF fosse in un formato grafico, come avrei potuto farlo?
Certo, i PDF in formato solo grafico ci sono stati: all’inizio i libri di Gallica, il progetto di digitalizzazione dei fondi della Biblioteca Nazionale francese, erano puramente scan fotografici salvati come PDF perché pare che era impossibile far capire a Jean-Noël Jeanneney, allora capo della BN, la differenza tra testo digitale e immagine digitale di testo. Erano anche date come PDF immagini tutte le prese di posizioni delle parti interessate durante la consultazione (2004-5) su una revisione parziale della legge svizzera sul diritto d’autore svizzero, radunate in https://www.ige.ch/index.php?id=528 .
Potrei citare un mucchio di altri esempi di PDF “immagini di testo” pre-2009, ca, roba da e-auto-da-fé. Ma oggi? In che senso sarebbero “grafici” tutti quei PDF che si possono scaricare dai tuoi post qui, e da tutte le pagine di tutti i wiki wikispaces.com – incluso http://loptis.wikispaces.com/ ?
Certo, non sono il massimo: i link appaiono sottolineati ma non si possono cliccare – come quando chiedi “stampa come PDF” a partire da un file .doc o .odt.
Ma se fai invece “esporta come PDF” a partire da un file .odt in LibreOffice (e presumibilmente da un file .doc o .docx in Word), nel PDF risultante i link, compresi quelli di navigazione interna, vengono preservati, come nel file testuale di partenza.
sto partendo per giocare con lavagne digitali sul Monte Amiata… a domani… 🙂
IL PDF è un sistema per produrre oggetti grafici, che possono essere vari tipi di oggetti, quali immagini bitmap intere – come tali “congelate” – o altri oggetti ancora quali per esempio caratteri, da mostrare con un certo font eccetera. Un file in PDF contiene all’interno istruzioni su come fabbricare la forma grafica di questi oggetti, proprio come un software grafico vettoriale, cioè, è un software grafico vettoriale, di fatto. Ed è proprio per il fatto che gestisce ciascun singolo carattere che tu scrivi come un oggetto a se stante, sempre ricostruibile graficamente, che tu lo puoi congegnare in maniera da rendere ad esempio possibile l’evidenziazione e l’estrazione di testi. In questo, PDF è un particolare tipo di software grafico vettoriale, specializzato per il trattamento di testi. Un software bitmap non ti permetterebbe di fare questo, naturalmente. Chi vuole approfondire può per esempio frugare qui. In fondo c’è un esempietto bellino con cui giocare – avevo fatto qualcosa di simile prima di rispondere e di trovare quel link…
Per i filtri. No, di per se un filtro non crea livelli, semplicemente parte dalla serie di numeri che rappresenta quel certo tipo di informazione, e ci fa dei conti sopra creando un’altra serie di numeri, anche molto diversi, che rappresenta l’oggetto iniziale filtrato, ovvero trasformato. Poi questo viene piazzato da qualche parte, in modi che dipendono da come è organizzato il software e poi da cosa gli dici di fare te.
Grazie! Comincio a intuire cosa avviene in un PDF . Adesso sto usando il tutorial http://www.printmyfolders.com/understanding-pdf che hai linkato per cercare di capire come funziona il contenuto dezippato del file https://ia700403.us.archive.org/16/items/WithALittleHelp/Cory_Doctorow_-_With_a_Little_Help_abbyy.gz – il primo che il software dell’Intert Archive aveva derivato dal PDF che avevo caricato in https://archive.org/details/WithALittleHelp.
Prima non capivo affatto perché il software andava a fare una cosa con abbyy, che serve per il riconoscimento ottico dei caratteri presentati come immagini, se io avevo caricato un PDF che credevo “testuale”. Brancolo ancora parecchio nel buio, però forse sarà legato a quel che tu spieghi, no?
Grazie anche per la spiegazione sui filtri.
Tutto così interessante soprattutto intorno alle immagini con cui lavoro spesso con i bambini a scuola: non solo come produzione ma anche come manipolazione, certamente quello che leggo è un mondo a me sconosciuto, in cui però ian piano posso immergermi alla ricerca di risposte ai miei perché: per es. perché l’immagine stampata non è più così chiara come mi sembrava sul monitor, perchè le dimensioni cambiano, come è meglio salvare le foto piuttosto che i disegni….
La lista è lunga, i miei vuoti da colmare profondissimi, ma avere riferimenti è un’occasione da non perdere, mi prenderò il tempo per farlo.
Giusi
MOlto interessante grazie. Ho scaricato gimp da tempo ma non ci ho ancora provato, Le istruzioni che vedo qui mi danno un po’ di coraggio magari stavolta ci provo. Su gimp a proposito so che faranno un corso online semi-gratuito su forumlive (certificato tra l’altro) a chi può interessare…
Lezione interessante. Ho provato a fare l’esercizio dei salvataggi zip.
Da che in formato word erano uguali, con la compressione sono venuti uno di 2979 byte e l’altro di 2339. Per tutto il resto non pensavo esistessero tutte queste differenze per le immagini. è facile prenderne una e caricarla/stamparla/copiarla senza sapere l’infinità di cose che vengono celate dietro le”quinte”. Appena avrò un po’ di tempo voglio proprio vedere come funzionano questi software e vedere per il meglio le differenze.
Leggo sempre con stupore e gratitudine questi articoli: oggi scopro che dietro ad una semplice immagine si aprono mondi, conoscenze, territori inesplorati.
Per gli autodidatti, come me, tutte queste informazioni colmano un vuoto di cui a volte non si è consapevoli, l’uso di alcune tecniche, modalità, formati ecc…avviene per intuito, per sentito dire, per tentativi, per prove ed errori, ma sfugge la vera conoscenza.
Mi è piaciuta molto anche la nota 5, la spiegazione del grafico e il riferimento a Vigotskij e alla sua zona di sviluppo prossimale e soprattutto alla descrizione di ciò che avviene in questo laboratorio che ho modo di sperimentare in prima persona.
Sono stata incuriosita infine dal link “appunti di lettura” che ho trovato nel commento di Claude, ho cliccato e mi sono ritrovata in Diigo: penso di avere un profilo in questo strumento, per qualche sollecitazione ricevuta in qualche insegnamento con la Iul, ma non ricordo perchè l’esperienza non ha avuto seguito: chissà che non sia il momento e l’occasione per colmare anche questo vuoto!
Un’ultmissima cosa: non mi è molto chiaro un passaggio nel capitoletto “Tipi di grafica”. Si dice che non sempre le immagini vengono memorizzate secondo la logica di elenco dei contenuti di pixel. Si danno due possibilità una grafica vettoriale (raster: griglia) e l’altra di grafica bitmap o grafica raster: non mi è chiaro a che cosa si riferisce il termine “raster”.
Grazie!
Grazie Antonella. Riguardo all’ultima cosa che dici, era un mio errore. Se ricarichi la pagina non lo dovresti vedere più. Grafica raster è sinonimo di grafica bitmap.
Oggi pomeriggio mi sono accorto che erano rimasti a giro anche altri errori. Una forma di dislessia? Eppure questi post li rileggo sempre due volte, prima di premere il tasto “Pubblica” – gesto minimo che separa il privato dal pubblico e che compio sempre con timore, perché so per certo che sarò costretto a uscire e correggere gli errori all’aperto. Non sono migliorato molto da 50 anni a questa parte… 🙂
Sì, non si vede più! Grazie!
…mi consola sapere che non solo a me capita di leggere, rileggere commenti, email, articoli e compiere con timore il comando di “invia” o “pubblica”, per poi scoprire che ci sono errori o imperfezioni.
(mia mamma dice sempre: ” Se non sbagliano i sapienti, che cosa devono fare i poveri ignoranti!”, naturalmente lo dice nel dialetto locale e il messaggio è sicuramente più efficace)
Ha ragione tua mamma: quanto ai refusi, ci sono anche nei libri di dottissimi rivisti e ririvisti da tanti curatori dottissimi. George Steiner pubblicò una seconda versione di After Babel nel 1992.. All’inizio, Steiner citava un sonetto di Dante Gabriele Rossetti, col titolo “Angelica saved by the dragon” anziché “Angelica saved by Ruggiero from the dragon”. Il refuso c’era già nella prima edizione del 1975, e quindi era sfuggito all’autore e ai curatori dell’Oxford University Press allora e di nuovo nella preparazione della nuova edizione, nonché ai traduttori e curatori di tutte le versioni in altre lingue pubblicate da altri editori nel frattempo, nonché ai numerosi lettori – me compresa, finché non ho dovuto fare un confronto frase per frase dell’inglese e dell’italiano, perché la Garzanti mi aveva incaricata di integrare le modifiche del 92 nella traduzione italiana fatta sull’edizione del 75.
Allora su “raster” mi ero chiesta anch’io se non ci fosse un simile refuso di spostamento, come l’avevo scritto in quella pagina https://diigo.com/01lqff che ti ha incuriosita.
Incuriosisce pure me questa funzione di di Diigo che consente di aggiungere appunti a passi di qualsiasi pagina web (vedi http://help.diigo.com/how-to-guide/sticky-note – grosso modo valido anche se in parte obsoleto). Quando partecipavo al blog pluri-autore etcjournal.com, avevamo avuto una discussione accesa su di essa, e su qualcosa di consimile offerto allora da Google. Un altro co-autore era scandalizzato che la gente potesse così annotare un suo testo e condividere il testo annotato con altri.
Avevo cercato di spiegare che il suo testo rimaneva intonso, che Diigo aggiungeva soltanto sopra una specie di foglio di plastica trasparente sul quale gli utenti potevano aggiungere quelle “sticky notes”, annotazioni appiccicose, in corrispondenza a passi evidenziati. Però questa è una metafora da tecno-analfabeta. È o non è la stessa cosa dei livelli (layers) che descrivi nel post, Andreas?
L’analogia regge per quanto riguarda l’indipendenza degli strati. Si può in effetti pensare che i “post-it” che Diigo appiccica sul sito stiano in una sorta di livello separato e sovrapposto. Di fatto Diigo la realizza scaricando la pagina del sito in una propria cache, una sorta di “memoria cassetto”, dove si appoggiano delle cose che servono per un certo periodo. Questo si vede per esempio da quello che Diigo scrive in cima alla pagina, per esempio i tuoi Appunti di lettura: This is a cached version of http://iamarf.org/2014/02/23/elaborazione-di-immagini-tre-fatti-che-fanno-la-differenza-loptis/. Diigo.com has no relation to the site.
Grazie! infatti non avevo mica capito quella frase sulla cached version, perché se la pagina viene aggiornata come hai fatto tu spostando la traduzione di “raster”, anche la versione Diigo con appunti aggiorna la pagina “sotto” gli appunti: in effetti ne avevo uno sulla posizione di quella traduzione, che adesso non si vede più in quei miei appunti di lettura (anche se l’appunto è rimasto tra quelli elencati nel segnalibro della pagina nel gruppo Diigo ltis 13) .
Ma se quella cached version è temporanea, allora si capisce.
Morale:
– Il trucco non serve per mantenere visibile tale quale ad es. un articolo di un giornale che li fa scomparire dalla visualizzazione pubblica a mezzanotte, tipo carrozza di Cenerentola.
– Però basterebbe evidenziare tutto il testo fetta a fetta con Diigo per conservarlo negli appunti del segnalibro.
– Da esplorare: cosa succede con un PDF pubblicamente visimile online ma con protezione anticopia.
Mamma mia, che cose interessanti avete scritto!
Vi ringrazio, entrambi!
Spero di avere un po’ di tempo per riprovare ad utilizzare Diigo e mi piacerebbe anche lavorare sulle immagini con i due sw, Gimp e Inkscape.
Interessantissimo. Appena terminati gli esami, mi tuffero’ . Informazioni preziosissime. Effettivamente sulle immagini non avevamo “giocato” !!! E’ arrivato il momento!!!
Grazie! Per ora ho preso degli appunti di lettura – Poi semmai ne traggo qualche domanda quando avrò capito meglio che cosa mi sfugge ancora.