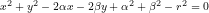L’idea è un po’ questa. Quando tocca fare un nuovo corso intorno alle information technologies eccetera eccetera, ai nuovi studenti mi vien fatto di dire – Entrate nel laboratorio, vi conduco a vedere gli strumenti e i servizi diversi per cui s’adoprano, qui c’è questo là c’è quello…
I materiali ci sono. Ciascuno se li può aggiustare a misura. Quello che cambia sono i modi di interazione. Gli studenti di medicina che arriveranno il 4 di marzo, in realtà mi vedranno in una serie di lezioni, quindi qualcosa cambia, ma non la sostanza – quanto alle lezioni non saranno proprio tali, diremo poi come.
È pensando a loro che ho scritto il seguente “indice ragionato”, in modo che possano individuare più facilmente un loro percorso nella foresta di questo blog. Ma credo che tornerà utile anche a tutti gli altri. Provvedo quindi a integrarlo nel settore “accoglienza” del blog. Intanto nella barra accanto trovate questo stesso indice riprodotto in una pagina apposita, a fianco del solito elenco cronologico dei post.
Anche questo è un esperimento interessante: l’estrazione di un corpus di contenuti da quello che alla fine è una sorta di racconto. Se li volessi rendere dei contenuti di sapore, per così dire, più accademico, li dovrei spolpare del racconto, ma… ecco, proprio non mi va…
È un capitolo dedicato primariamente agli studenti di medicina e a chiunque abbia qualche necessità di accedere alla letteratura scientifica. È ulteriormente suddiviso in 8 parti:
discussione sul metodo scientifico e sulla sua letteratura
introduzione a Pubmed
motore di ricerca su vari database di scienze biomediche
un esempio di ricerca
impiego del proxy di ateneo per l’accesso alle riviste in abbonamento presso la biblioteca medica – questo può essere utilizzato da chiunque per capire in generale una funzione importante dei proxy
il problema dell’accesso limitato e costoso alla letteratura scientifica
un articolo sullo stesso tema di George Monbiot, giornalista del Guardian
come usare i web feed per tracciare in Pubme le novità pubblicate su specifici argomenti
I materiali sono estratti da corsi degli anni precedenti, quindi si riferiscono a contesti passati, e alcuni particolari relativi all’interfaccia di Pumed possono essere cambiati – succede spesso ma i contenuti essenziali sono semprevalidi.
Clicca qui per scaricare la versione in pdf (1.8MB)
Sicuramente un post per gli studenti di “Editing multimediale” della IUL ma anche per tutti quelli a cui capita di lavorare con le immagini
Grafica bitmap e vettoriale
Due o tre cose sui formati più noti, GIF, PNG e JPEG, sulla compressione delle informazioni, conservativa e non, e sui formati “dedicati” XCF e SVG
Gimp e Inkscape, due bellissimi software liberi per l’elaborazione delle immagini che girano su Linux, Mac e Windows
Elaborazione delle immagini in livelli
Primo fatto: software libero anziché proprietario
Il fatto che il software sia libero o proprietario è fondamentale, per motivi etici prima ancora che tecnici. L’espressione sintetica di Marina è perfetta:
software libero vuol dire che rende le persone più libere
Aggiungo: la scuola e l’università hanno il dovere morale di dimostrare, diffondere e promuovere il software libero. Il resto l’abbiamo detto in un post precedente.
Secondo fatto: distinguere fra grafica bitmap e vettoriale
Immagini digitali
Le immagini digitali sono sempre formate da una sorta di scacchiera di piccoli quadratini denominati pixel, il cui interno è rappresentato con un colore uniforme al quale nel computer corrisponde un certo valore numerico. Anche se le immagini sono monocromatiche vale lo stesso concetto. Per fare un esempio noto a tutti, le immagini TAC (Tomografia Assiale Computerizzata) sono rappresentate in scale di grigi. Ebbene, anche lì in ogni pixel, l’intensità di grigio è in relazione con un numero che rappresenta (con una certa approssimazione) la densità media dei tessuti del corpo nella spazio rappresentato da quel pixel.
dpi e risoluzione
In qualsiasi immagine digitale potete scorgere i pixel, se vi avvicinate o la ingrandite a sufficienza. Naturalmente è proprio quello che non si vuole vedere, di solito. In questo articolo useremo il termine risoluzione per il numero di pixel dell’immagine – maggiore risoluzione significa maggior numero di pixel. In realtà, il concetto di risoluzione spaziale di un’immagine è differente e molto più complesso ma qui ci atterremo alla prassi corrente per rendere il discorso più agile e compatto. Invece con dimensione intenderemo la grandezza del file in cui l’immagine viene memorizzata, e potrà essere espressa in Mega Byte (MB) o in Kilo Byte (KB) [1].Per esempio se fate una scansione di un documento o un’immagine dovete fare attenzione al parametro dpi (dots per inch, punti per pollice). Un pollice sono 2.54 cm e valori accettabili stanno usualmente fra 100 e 200 dpi, ma dipende da cosa dovete scannerizzare. Occorre quindi fare delle prove scegliendo il valore più basso che dà la qualità adeguata, nel contesto che vi interessa. Non vale esagerare, perché la dimensione delle immagini cresce grandemente in proporzione inversa alle dimensioni dei pixel: se i pixel di un’immagine sono più piccoli vuol dire che ve ne saranno di più – se scelgo 200 dpi anziché 100, vuol dire che su ogni lato dell’immagine ho il doppio dei pixel, quindi il numero totale dei pixel dell’immagine sarà 2×2=4 volte più grande, ergo raddoppiare la dimensione lineare vuol dire quadruplicare la dimensione dell’immagine, e quindi anche la dimensione del file dove questa viene memorizzata. Infatti, dal punto di vista del computer, un’immagine digitale è semplicemente una fila di numeri, tanti quanti sono i pixel in cui è suddivisa. Quando il computer la deve rappresentare su un qualche supporto – monitor, stampa… – allora legge i numeri a partire dal primo e decodifica ciascuno di essi in maniera da produrre l’effetto dovuto, in termini di colore e intensità, poi li “scrive” nello spazio dell’immagine come si fa nelle lingue occidentali: da sinistra a destra, dall’alto al basso.
Tipi di grafica
Ma non sempre le immagini vengono memorizzate secondo la logica di un “elenco dei contenuti dei pixel”. Si danno infatti due possibilità, una che prende il nome di grafica vettoriale e l’altra di grafica bitmap, o grafica raster (raster: griglia; da qui in poi utilizzeremo il termine bitmap). Le immagini bitmap sono memorizzate così come abbiamo già detto. Ad esempio le fotografie e le immagini mediche sono di questo tipo. Le immagini vettoriali sono invece memorizzate attraverso una rappresentazione ad oggetti. I disegni CAD (Computer Assisted Design) fatti da un progettista e i documenti PDF sono esempi di immagini vettoriali. Facciamo un esempio affinché la differenza sia chiara.
Grafica bitmap
Supponiamo prima di disegnare una circonferenza con un software di tipo bitmap, poi immaginiamo di ingrandire molto l’immagine: prima o poi la circonferenza rivelerà la struttura in pixel, che le darà un aspetto frastagliato.
Immagine di una circonferenza generata in grafica bitmap. L’immagine di destra rappresenta l’ingrandimento del quadrato rosso raffigurato nell’immagine di sinistra.
Grafica vettoriale
Disegnate ora la stessa circonferenza con un software di tipo vettoriale e provate a ingrandire l’immagine a piacimento: la circonferenza sarà sempre lì, con gli stessi identici attributi che le avrete assegnato all’atto della sua creazione. Magari ne vedete solo un piccolo arco perché avete ingrandito l’immagine veramente tanto, ma non vi sono artefatti.
Immagine di una circonferenza generata in grafica vettoriale. L’immagine di destra rappresenta l’ingrandimento del quadrato rosso raffigurato nell’immagine di sinistra.
Perché questa differenza? Il software di tipo bitmap parte da un’immagine che è tanti pixel alta e tanti pixel larga. Dopodiché qualsiasi cosa facciate, il software si preoccupa di riempire i pixel come dite voi. Altro non fa. Se avete chiesto di disegnare una circonferenza, il sistema utilizza l’equazione matematica della circonferenza
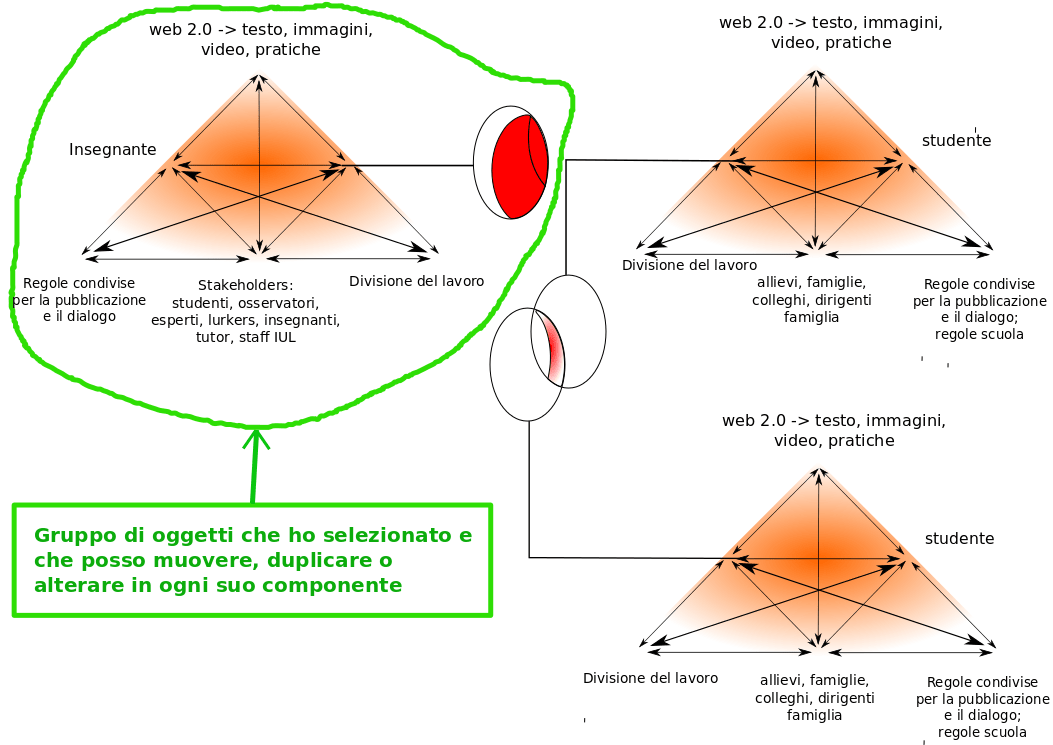
dove α e β sono le coordinate del centro e r è il raggio della circonferenza, per riempire appropriatamente i pixel. Poi se ne dimentica, ovvero dimentica i suoi parametri, α, β e r [2]. Invece, il software di tipo vettoriale, utilizza l’equazione della circonferenza per disegnarla sullo schermo, con i parametri di rappresentazione correnti, ovvero riempie i pixel che voi vedete sullo schermo, e invece di memorizzarne i contenuti memorizza l’equazione della circonferenza, sotto forma dei suoi parametri α, β e r, e di altri eventuali attributi grafici, quali spessore e colore della linea. Poi, ogni volta che voi rinfrescate l’immagine sullo schermo, ricaricandola o variandone le dimensioni, ricalcola i contenuti dei pixel a partire dall’equazione della circonferenza. E così per tutti gli altri oggetti.
Riassumendo, con la grafica bitmap il sistema ricorda i contenuti di tutti i pixel dell’immagine – quando la deve rappresentare sul schermo costruisce l’immagine semplicemente rappresentando adeguatamente i singoli pixel. Con la grafica vettoriale il sistema ricorda l’idea di circonferenza, ovvero di quella precisa circonferenza con il centro posizionato in quella certa posizione, con quel certo raggio, con quel certo spessore e quel certo colore con cui deve essere tracciata – quando deve rappresentare l’immagine, prima calcola i contenuti dei pixel per rappresentare quella circonferenza, poi rappresenta i pixel così calcolati sullo scheermo.
Formati – compressione
Non vogliamo perderci qui nella foresta dei formati. Se necessario approndiremo dove opportuno. Solo gli esempi comuni. Tutte le immagini di origine fotografica sono gestite e memorizzate con la logica bitmap. È naturale: derivano tutte da una qualche matrice di rivelatori, intendendo per matrice una qualche precisa disposizione di rivelatori di radiazione elettromagnetica: luminosa, infrarossa, X o altro. I formati più comuni per la distribuzione di immagini bitmap nel web sono GIF, PNG e JPEG – detto anche JPG, è lo stesso.
Qui occorre un inciso sulla compressione. Le immagini – anche l’audio e a maggior ragione il video – contengono molta informazione, quindi i file tendono ad essere grandi – oggi si ama dire che sono “pesi”. Persino la fotocamera di un telefono produce immagini di vari milioni di pixel. Far viaggiare questa roba in internet può essere un problema, a maggior ragione per chi vive in paesi sottosviluppati – o “diversamente sviluppati”, come il nostro, duole dirlo ma all’atto pratico, fra la velocità di trasferimento subalpina e quella sovralpina può corre tranquillamente un fattore 10. Le tecniche di compressione dell’informazione sono quindi fondamentali, è grazie a queste che la distribuzione dell’informazione multimediale è esplosa, ad esempio nei formati MP3 (audio), JPEG (immagini) e MP4 (video). Tutti questi esempi – sono i più comuni ma ve ne sono tanti altri – sono caratterizzati dal fatto di impiegare un qualche sistema di compressione dell’informazione. E tutti e tre usano i sistemi di compressione più efficaci, ovvero quelli non conservativi, che per comprimere meglio buttano via qualcosa – qualcosa che non si sente nell’audio, che non si vede nelle immagini o nei video. Sono sistemi regolabili – se si esagera si finisce col deteriorare il messaggio.
Con la compressione conservativa invece non si butta via nulla, ma si sfruttano ripetizioni e regolarità, sfruttandole in modo intelligente. Ci capiamo subito con questo esempio: pensate a un’immagine fatta da un solo pixel centrale nero e tutti gli altri bianchi – non è interessante ma è utile per capire. Non è difficile immaginare un sistema abbastanza furbo da memorizzare il numero di pixel che sono uguali e il loro (unico) valore. Nel nostro esempio significa che invece di memorizzare milioni di numeri, basta memorizzare il numero dei pixel bianchi, il numero di quelli neri e i due valori corrispondenti al bianco e al nero: 4 numeri! Abbiamo semplificato molto ma il concetto c’è, ed è anche sufficiente a capire che il successo di questi metodi dipende dal tipo di immagine. Per esempio in un’immagine fotografica piena di sfumature morbide ci sarà poco da comprimere. Un esempio di compressione conservativa molto noto è quello del formato ZIP. Può valer la pena di fare un giochino. Prendo un brano di questo scritto, lo salvo in un file con un editore di testo – un editore di testo, non Word! – Mi è venuto un file di 1075 byte. Sempre con l’editore di testo scrivo “pippo pippo…” tante volte (alla Shining – non mi sta vedendo nessuno…) fino a ottenere un file egualmente lungo, ovvero di 1075 byte. Applico a tutti e due lo zip: nel primo caso viene un file di 725 byte e nel secondo di 173 byte. Potete provare anche voi per esercizio, inventandovi degli esempi simili, o scaricando il file numero 1 e il file numero 2 per zipparli da voi.
Dunque dicevamo che i formati più comuni per la distribuzione di immagini bitmap nel web sono, GIF, PNG e JPEG. Vediamoli brevemente.
Il formato GIF usa una compressione conservativa. Questo lo rende adatto a immagini che contengono testo o grafica composta da linee. Si può usare per fare immagini animate.
Anche il formato PNG comprime l’immagine in modo conservativo e quindi anche questo è adatto nei casi cui sono presenti testo o linee. È meglio rispetto al GIF perché è più recente: consente di rappresentare le immagini con maggiore qualità e le comprime meglio. Non si possono però fare immagini animate, per questo ci vuole il formato GIF. In fondo vedremo un esempio.
Il formato JPEG applica invece una compressione non conservativa. È il formato adatto alle immagini fotografiche. Se siamo noi a generare un file JPEG, allora all’atto del salvataggio si può scegliere il grado di compressione. Occorre controllare quindi: più si comprime e più l’immagine può risultare degradata, specialmente se vi sono dettagli fini e contrasti bruschi.
Per quanto riguarda la grafica vettoriale occorre certamente citare il PDF. È un’ottima occasione per puntualizzare che il PDF è un formato grafico, e per di più vettoriale, perché molti scambiano il PDF per una variante del formato DOC – quello di Word, o altri word processor. No, il PDF non è un formato di testo o testo formattato, bensì è un formato grafico: esportare un documento qualsiasi – testo, foglio di lavoro o altro – in PDF vuole dire farne una sorta di fotografia, ovvero congelarlo in un’immagine, e per di più un’immagine vettoriale, perché così risulta meno sensibile alla modalità con la quale viene rappresentato, grazie al meccanismo ad oggetti che abbiamo visto. Perché il PDF è nato proprio per diffondere documenti nella rete, in maniera che questi rimangano inalterati, indipendente dal supporto di visualizzazione o dalla modalità di stampa.
Manipolando foto
La questione del formato è particolarmente importante quando siamo noi che creiamo le immagini. Le immagini si possono presentare in una grande varietà di forme, agli estremi abbiamo le fotografie da un lato e i “disegni al tratto” dall’altro – diagrammi, grafici. Di foto ne produciamo tutti tante, anche troppe. La tendenza è scattare e riempire memorie – pensa a tutto la macchina. In realtà anche in un cellulare di fascia bassa si può intervenire su alcuni parametri, per non parlare degli smartphone. Sicuramente si possono determinare numero di pixel e qualità dell’immagine. La dimensione dei file cresce con il numero dei pixel e la qualità dell’immagine. La qualità è di fatto regolata mediante il rapporto di compressione JPEG. Prima di usare l’apparecchio, non sarebbe male fare delle prove, ripetendo lo stesso scatto con risoluzioni e qualità diverse, per poi scegliere i parametri che consentono di ridurre le dimensioni dei file ma senza introdurre artefatti nell’immagine.
Chi ha qualche velleità fotografica e utilizza macchine “serie” – reflex, street photography, grandi formati – ha certamente a disposizione l’opzione del formato cosiddetto RAW –raw data: dati grezzi. Questi sono i numeri letti direttamente dai sensori dell’apparecchio, sui quali si può lavorare successivamente con gli appositi software di elaborazione fotografica. È il formato prediletto da chi vuol partecipare alla costruzione dell’immagine fotografica, un po’ come coloro che amavano sviluppare le proprie foto nella camera oscura. Con il formato RAW la libertà di espressione è maggiore ma anche la dimensione dei file è molto più grande dei file JPEG – meno scatti, più riflessione post processing – ex camera oscura – più qualità.
Fabbricando immagini
Diverso è il caso in cui le immagini ce le dobbiamo fabbricare “a mano”. Qui la risposta non è univoca perché dipende da quello che si deve fare. Nel caso di diagrammi o grafici, quasi certamente conviene optare per un formato di tipo vettoriale. Costruendo invece immagini composite nelle quali gli elementi fotografici sono importanti, allora probabilmente si può lavorare sia in forma vettoriale che bitmap – la scelta dipende dal tipo di fruizione dei risultati e, in ultima istanza, dalle preferenze personali.
Lavorare in forma grafica bitmap o vettoriale vuol dire usare software diversi. Qui citiamo due ottimi software liberi: Gimp per la grafica bitmap e Inkscape per la grafica vettoriale. La quantità e varietà di software e di servizi web per l’elaborazione delle immagini è impressionante. Molti conosceranno Photoshop per il ritocco delle immagini fotografiche, e forse avranno sentito nominare Autocad per la progettazione, quali esempi di software per grafica bitmap da un lato e vettoriale dall’altro, anche se quest’ultimo più di nicchia e strettamente professionale. Sono programmi dal prezzo elevato, probabilmente ingiustificato per la maggioranza delle finalità che può avere un utente generico. In realtà le alternative libere Gimp e Inkscape sono molto sofisticate e possono essere usate con profitto anche in contesti professionali. Gli esempi precedenti, dove abbiamo mostrato cosa succede ingrandendo immagini dei due tipi sono stati realizzati con questi due software, ma vediamo qualche esempio per dare un’idea delle potenzialità e delle differenze fra le due modalità.
Lavorare in grafica bitmap con Gimp
.
Questa immagine – chi vuole sapere di che si tratta può leggere la nota [3] – è stata è stata scattata con un apparecchio comune, di quelli automatici, nemmeno più tanto recente, e ciò nonostante già in grado di sparare immagini di 4320×3240 pixel, come questa che vedete qui sopra, espressa in tre diversi formati, da sinistra a destra: PNG – compressione conservativa, cioè nessun degrado ma il file occupa 19MB; JPEG con compressione ridotta (94
Ma la differenza c’è, dipende da come si intende usare l’immagine, in particolare da quanto si pensa di ingrandirla. Le tre immagini sopra sono scalate per farle entrare nel post, cliccando sopra appaiono le versioni originali, sulle quali potete cliccare un’altra volta per ingrandirle ulteriormente. Se con il vostro browser non funziona così, potete scaricarle sul vostro computer e poi ingrandirle con il software di visualizzazione di immagini che usate di solito. Ebbene, vedrete che, ingrandendo molto, se fra le versioni PNG (a sinistra) e JPEG 94
Ma vediamo ancora più in dettaglio come stanno le cose, confrontando un particolare dell’immagine senza alterazioni, con risoluzione ridotta, con compressione JPEG e con tutti e due i trattamenti.
1) immagine originale ad alta risoluzione 4320×3240 pixel, dimensione 19 MB; 2) sempre ad alta risoluzione ma molto compressa con JPEG, dimensione 213 KB; 3) a risoluzione ridotta del 20
Per vedere bene gli effetti occorre cliccare sull’immagine qui sopra, che è scalata per farla entrare nell’impaginazione, e poi cliccare nuovamente sull’immagine che appare per ingrandirla ulteriormente.
Ebbene, se la dimensione del file dell’immagine originale era di 19 MB, sia riducendo la risoluzione del 20
Quindi, primo messaggio: per ridurre il “peso” di un’immagine si può agire sul parametro di qualità-compressione del formato JPEG ma occhio alla risoluzione: se i pixel sono pochi il rischio di rovinare l’immagine è alto, quindi bisogna essere prudenti: andare per tentativi e errori.
Secondo messaggio: per lavorare bene, può avere senso porsi il problema se convenga ridurre le dimensioni riducendo la risoluzione oppure comprimendo di più con il JPEG. Si confrontino le immagini 2), compressa con JPEG, e 3), alleggerita riducendo la risoluzione. La prima ha i contorni più conservati mentre si sono praticamente perse le sfumature delle superfici piane. Nella seconda le sfumature delle superfici sono ancora ben rappresentate ma i contorni sono deteriorati dalla dimensione dei pixel – meno pixel vuol dire pixel più grossi. Da tutto questo si vede come in ambedue i casi la riduzione delle dimensioni dell’immagine sia stata ottenuta al prezzo della perdita di una certa quantità di informazione, ma che tale perdita è qualitativamente diversa nei due casi. La riduzione della risoluzione tende a sciupare i contorni, la compressione JPEG tende a sparpagliare la degenerazione nell’immagine. L’indicazione pratica che se ne ricava è che nel caso di immagini morbide e con poche variazioni brusche di contrasto conviene ridurre la risoluzione, ovvero il numero di pixel; invece nel caso di immagini dove predominano linee e contorni forti, può convenire ricorrere ad una compressione JPEG più energica. In ogni caso: domandarsi come verrà usata l’immagine e cosa vogliamo comunicare e poi andare per tentativi ed errori, perché gli effetti cambiano a seconda del tipo di immagine.
Chi si cimenta nell’uso di Gimp si accorge che fra i 40 formati nei quali può salvare un’immagine, il primo che viene proposto è XCF. Questo è il formato nativo di Gimp, ovvero quello che è in grado di memorizzare tutte le informazioni fra una sessione di lavoro e l’altra. È il formato da usare quando si lavora con un’immagine e la vogliamo mantenere per ritornarci a lavorare in futuro – se la memorizziamo in questo formato siamo sicuri di ritrovare tutta quello che abbiamo fatto in precedenza. Non è il formato da usare per inviare un’immagine in rete, a meno che uno non voglia condividerla con qualcun altro che debba continuare a lavorarci con Gimp. Il processo corretto quindi è quello di memorizzare tutte le varie versioni dello sviluppo in XCF e poi esportare il risultato in un formato idoneo a essere trasmesso, per esempio GIF, PNG, JPEG o altro.
Resterebbe da dire qualcosa sulle elaborazioni in grafica bitmap, ma vedremo meglio dopo, ragionando del terzo fatto che fa la differenza, in materia di manipolazione di immagini.
Lavorare in grafica vettoriale con Inkscape
Le immagini si possono creare anche in grafica vettoriale. Anche per questo tipo di elaborazione esiste uno splendido software libero, che è Inkscape. Vediamo un esempio.
Esempio di tipica immagine che conviene produrre in grafica vettoriale. Questa è stata prodotta con il software libero Inkscape. Clicca l’immagine per vederla meglio.
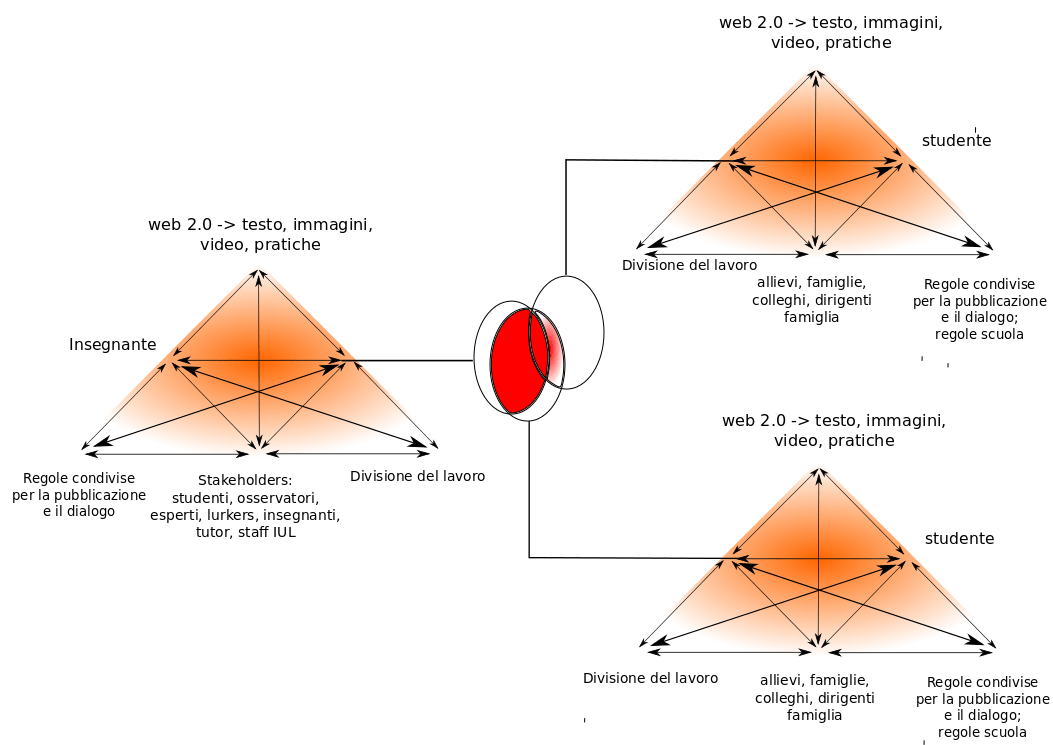
Il soggetto dell’immagine non ci interessa qui, se non per come è stato costruito graficamente. Chi fosse incuriosito dal senso del diagramma può leggere una breve nota [5]. Come abbiamo già visto, nella modalità vettoriale, ad essere memorizzati non sono i pixel dell’immagine ma le caratteristiche geometriche degli oggetti – in questo caso triangoli, ellissi, segmenti di vario tipo, sfondi, testi. È una modalità comodissima per fabbricare un diagramma del genere. Una volta costruito un triangolo, con le sue frecce, il suo sfondo e i testi, per fare gli altri, basta raggruppare tutti gli elementi con una semplice riquadratura e duplicare il tutto, spostare la copia nella posizione desiderata e poi intervenire sui singoli elementi che debbano essere eventualmente cambiati, per esempio i testi in questo caso. Ciò è reso possibile dal fatto che il sistema tiene traccia di ogni singolo oggetto e di ogni sua caratteristica, in un modo che rende molto semplice manipolarlo, riprodurlo e nuovamente alterarlo in ogni successiva fase del lavoro:
Esempio di come, in grafica vettoriale, sia facile selezionare un gruppo di oggetti, per poi spostarlo, replicarlo o modificare in ogni suo componente. Cliccare l’immagine per vederla meglio.
Fra i casi estremi che abbiamo mostrato esiste tutta una zona intermedia di risultati che possono essere raggiunti con ambedue i sistemi. Per averne un’idea può essere interessante andare a vedere in DeviantART – un social network dedicato alle creazione grafiche – i lavori fatti sia dagli appassionati di Gimp che da quelli di Inkscape.
Anche Inkscape ha un formato di riferimento che conserva tutto ciò che serve per conservare il lavoro fra sessioni successive, è lo SVG. Valgono le stesse considerazioni fatte a proposito del formato XCF di Gimp. La differenza con Gimp è che Inkscape non offre formati che comprimono in modo non conservativo – per esempio si può salvare in PNG ma non in JPEG. Del resto, se vogliamo, il formato vettoriale opera intrinsecamente una forma di compressione, memorizzando solo i parametri geometrici degli elementi presenti anziché i contenuti dei pixel, che sono quasi sempre centinaia di migliaia o milioni. Ad esempio, l’immagine precedente, che è anche abbastanza complessa, è composta da 780’000 pixel ma il file in formato SVG occupa solo 85 KB. Se poi uno volesse comprimere ulteriormente un’immagine prodotta in grafica vettoriale usando il formato JPEG, per qualche giustificato motivo, non ha che da prendere la versione in PNG, caricarla in Gimp e da lì salvarla in JPEG, con il grado di compressione desiderato. Lo faccio, esagerando, per far vedere ancora il tipo di degenerazione che può venir fuori. Il file in JPEG è diventato di 29 KB ma…
Esempio del modo in cui si deteriora un’immagine prodotto in grafica vettoriale applicandole un’eccessiva compressione JPEG. Qui l’immagine è stato prodotta lavorando con Inkscape sul suo formato nativo SVG, poi è stata esportata nel formato tipo bitmap PNG, che comprime in modo conservativo, quindi è stata caricata in Gimp per essere infine salvata in formato JPEG con qualità del 10
Terzo fatto: usare i livelli (layers)
Infine il terzo fatto che fa la differenza in materia di elaborazione di immagini: l’esistenza dei livelli (layers). I livelli consentono di costruire un’immagine attraverso la sovrapposizione di piani contenenti elementi diversi di quella che sarà l’immagine risultante. Un caso tipico può essere quello della sovrapposizione di scritte ad un’immagine fotografica: la fotografia sta in un piano e i testi da sovrapporre stanno in altri piani.
Quello dei livelli è uno strumento potentissimo. Un vantaggio fondamentale è la facilità con cui si può intervenire in tempi successivi solo su alcune parti delle immagini. Cambiare un testo ormai integrato in una fotografia può essere un incubo. Cambiarlo nel suo piano, lasciando tutto il resto inalterato, è un gioco da ragazzi.
Vediamo un esempio costruito sulla solita immagine della locomotiva.
Questa immagine è stata costruita con Gimp in 4 livelli: il primo contiene la fotografia resa monocromatica, il secondo contiene solo il fumo che spiffera dai meccanismi, reso in rosso, il terzo contiene gli elementi grafici in verde e il quarto i testi in giallo.
Le possibilità offerte dai livelli sono sterminate. Per esempio, sempre con Gimp, non è difficile ottenere dalla precedente un’immagina animata in GIF:
Anche il programma in grafica vettoriale Inkscape offre l’elaborazione in livelli. Tuttavia, siccome nella grafica vettoriale ogni oggetto rimane indipendente e può sempre essere riacciuffato successivamente, da solo o in gruppo, i livelli giocano un ruolo un po’ minore, anche se in certe circostanze possono tornare molto utili. Nella grafica bitmap invece l’esistenza dei livelli cambia la vita a chiunque voglia fare qualcosa di appena più elaborato di un semplice ritocco.
Coda
Non ho dato istruzioni per l’uso – come si fa a fare questo o quello. Non credo che si impari per istruzioni preconfenzionate ma per suggestioni. Se la suggestione per qualcuno c’è stata allora costui proverà a fare qualcosa. Se avrà problemi lo scriverà, e noi lo aiuteremo.
Note
B: byte = 8 bit; 1 KB = 1024 B; 1 MB = 1024 KB; quindi 1 MB = 1024 x 1024 B, approssimativamente 1 MB è qualcosa più di un milione di B.
Per chi ha poca dimestichezza con il linguaggio matematico. L’equazione dice molto semplicemente che il risultato dell’operazione a sinistra dell’uguale, deve essere uguale a ciò che c’è alla sua destra, vale a dire uguale a 0. L’operazione a sinistra non è altro che una somma algebrica (vale a dire che c’è anche roba col segno meno) di alcuni termini, che sono a loro volta prodotto di alcuni fattori: x2 vuol dire x moltiplicato x, 2αx vuol dire 2 moltiplicato α moltiplicato x, eccetera. α, β e r sono le cose fisse, i cosiddetti parametri. Sono fisse nel senso che se io attribuisco a ciascuna di esse un valore, allora ho definito una precisa circonferenza, all’interno del mondo di tutte le infinite possibili circonferenze possibili. Rimangono x e y. Queste sono le variabili, quelle che servono a disegnare la circonferenza su un pezzo di carta o sullo schermo del computer, in questo caso. In sintesi, il software considera x e y come le coordinate dei pixel sullo schermo, esattamente come nella battaglia navale o in una carta geografica. Poi si “diverte” a “provare” vari valori della x, risolvendo l’equazione, cioè trovando la y in modo che valga l’uguale. Trovata così la y per ogni x, usa tali valori per individuare il pixel di tali coordinate e lo riempie di colore. Così viene fuori la circonferenza. Questa è una descrizione un po’ semplificata ma è corretta.
Interno cabina della locomotiva a vapore HG 3/4 Nr. 1 “Furkahorn”, fabbricata in Winterthur (CH) nel 1913 per operare sulla tratta a scartamento ridotto di alta montagna Brig-Furka-Disentis, successivamente venduta in Vietnam nel 1947, dove ha lavorato fino al 1993, anno nel quale è stato riportata in Svizzera per viaggiare sulla linea Oberwald-Furka-Realp, da allora operativa nella stagione estiva
I programmi che consentono di salvare immagini nel formato JPEG offrono sempre la possibilità di determinare la qualità regolando il compromesso compressione-qualità mediante un fattore numerico. Talvolta questo fattore è espresso come una percentuale che va da 0 a 100, ma attenzione, questo non rappresenta il fattore di compressione del file risultante ma solo un indice numerico che esprime il livello del suddetto compromesso. Programmi diversi quantificano in maniera diversa tale compromesso, che delle volte è espresso in termini differenti da quello percentuale. Quindi, quando si salva un’immagine in JPEG, dire che si è usato quel certo livello di compressione non vuol dire nulla se non si specifica anche con quale software è stato ottenuto. Ecco perché nel testo abbiamo specificato per esempio “10
Il diagramma rappresenta un tentativo ingenuo del sottoscritto di descrivere l’attività dell’insegnante nel cMOOC #ltis13 sulla base dell’activity theory di Yrjö Engeström. Giusto per dare un’idea di cosa rappresenti il diagramma, in maniera estremamente sintetica: i triangoli sono una generalizzazione del concetto di azione mediata di Vygotzky, rappresentata con un triangolo che descrive come il soggetto agisca sull’oggetto attraverso una mediazione complessa, realizzata mediante artefatti complessi, strumenti o simboli. Tale generalizzazione prende il nome di activity system e tiene conto del fatto che un soggetto agisce sempre all’interno di un sistema e che la descrizione delle sue azioni rappresentano una particolare prospettiva di quella che in realtà poi risulta un’attività del sistema. Facendo riferimento al triangolo di sinistra, per esempio un insegnante opera in un sistema caratterizzato da precisi insiemi di collaboratori (in basso al centro) che condividono un certo sistema di regole (vertice basso sinistro) e operano secondo una determinata divisione del lavoro (vertice basso destro), producendo, mediante un sistema di strumenti e simboli (vertice alto), un intervento che dovrebbe intercettare le domande e le necessità degli studenti, all’interno dalle loro rispettive zone di sviluppo prossimale.
Il 22 dicembre nel post Servizi di scrittura collaborativa e un primo progetto avevamo proposto l’idea di tradurre in collaborazione un articolo dall’inglese. L’idea consentiva di fare esercizio di editing in un wiki e allo stesso tempo di offrire materia di riflessione sull’aggiornamento professionale degli insegnanti in una modalità particolarmente coinvolgente.
L’articolo si intitola Expanding the zone of reflective capacity: taking separate journeys together – Espandendo la zona di capacità riflessiva: unendo percorsi diversi. È apparso nel 2009 sulla rivista Networks – An Online Journal for Teacher Research.
Poi il lavoro è andato sobbollendo grazie alla collaborazione di varie persone e alla cura continua di Claude. Ora è stato completato, grazie al contributo finale di Simona che ha estratto una versione ripulita dall’intrico di pagine che si era formato cammin facendo.
Intendiamoci, come dice Claude – che di traduzioni e di Lettere se ne intende – una traduzione non finisce mai. E noi lasceremo che chiunque voglia, possa contribuire a migliorarla, ove opportuno. Ma qui non dobbiamo dare qualcosa alle stampe, bensì solo consentire a tutti di accedere al contenuto dell’articolo – è in questo senso che possiamo ritenere completato il lavoro. Per chi volesse controllare la traduzione sulla carta, ecco i file pdf della versione inglese e della versione italiana. Chi volesse poi intervenire sulla versione finale oppure commentarla, può accedere alla versione preparata da Simona nel wiki.
Se non vado errato, al lavoro di traduzione hanno collaborato 13 persone, che hanno creato 8 pagine revisionate in totale 133 volte, e che hanno comunicato fra loro nel wiki con 191 commenti. Non male! Ringraziamo quindi:
Se ho dimenticato qualcuno o qualcosa segnalatelo, aggiornerò conseguentemente questo post.
Quanto al contenuto, l’articolo narra del lavoro conclusivo di un percorso formativo, nel quale un gruppo di insegnanti, eterogeneo per disciplina e scuola, accetta di confrontarsi filmando alcune lezioni nelle rispettive classi e discutendole criticamente insieme. A me era parso un approccio formidabile e coraggioso, che faccio fatica ad immaginare nel nostro contesto – sto pensando al mio, naturalmente, ma credo che nella scuola non sia molto diverso. Mi piaceva sapere cosa pensavano le persone… ora lo possono leggere tutti.
L’andare per scuole attiene alle attività di questo laboratorio. Un’attività da centellinare perché gli eventi in presenza costano tempo. Ma un’attività importante perché aiuta a capire chi c’è “dall’altra parte”, in che contesto si affannano quelle persone che scrivono e si agitano dietro a questo schermo. È un lavoro che mi rende un po’ assente, ma è rivolto sempre al medesimo obiettivo, quindi mi pare giusto scrivere una minima traccia di quello che bolle in pentola.
Forse non è stato molto intelligente lasciarsi coinvolgere in due eventi all’inizio di marzo, contemporaneamente all’inizio delle lezioni di informatica a 300 studenti di medicina, e a un’altra attività didattica sempre a medicina, e con la ferma intenzione di procedere con continuità qui dentro. Ma le occasioni capitano, e queste, anche se non sono “istituzionali”, mi sembrano importanti.
Allora, il I di marzo sarò nella scuola di Castel del Piano a mostrare lavagne digitali. È la scuola dove ci sono Nicoletta Farmeschi e Antonella Coppi, che fanno parte di questa comunità.
Poi l’8 di marzo andrò a ragionare di rete in un liceo di Pontassieve, per dare una mano a Giovanna Danza che si sta impegnano su questo fronte – lei ha partecipato al cMOOC #ltis13.
Qui di seguito scrivo la traccia in divenire di quello che intenderei dire e fare a Castel del Piano. Magari qualcuno mi dà qualche idea.
Dimostrazione di lavagne digitali “non lim”
Introduzione sul software e hardware libero
Pur prendendo una posizione nettissima a favore del software libero – del resto uso molto poco il mouse e digito comandi Unix da quarant’anni – infatti andrò snocciolando qualche fatto, sulla falsariga de Il software libero ti libera, sostenendo poi che
scuola e università hanno il dovere morale di dimostrare, diffondere e promuovere il software libero
proporrò tuttavia un approccio non talebano, bensì progressivo – meglio insinuare il dubbio e far breccia in 1000 ignari che ordinare 10 nuovi sacerdoti – illustrando brevemente quattro livelli di coinvolgimento
Dimostrazione di lavagne digitali facili o economiche
In tale contesto, cercherò di mostrare varie opzioni possibili, fra quelle particolarmente facili o economiche – economiche rispetto alle soluzioni commerciali chiavi in mano. E quando vi saranno più opzioni, privilegeremo quelle più facilmente e sicuramente implementabili. È roba che sto imparando a usare, non è detto che andrà tutto diritto, per cui invoco perdono in anticipo a chi subirà questo esperimento…
Mostreremo un proiettore che funziona in modo interattivo e poi in modalità non interattiva ma con l’ausilio del telecomando Wiimote. Mostreremo l’uso sia con Windows che con WiildOs. Proporremo una progressione dove, passando da una soluzione a quella successiva, aumenta sì la difficoltà ma si guadagna in etica e valore didattico.
Consapevole di avere citato solo alcuni dei software esistenti. Aperto a suggerimenti, che se validamente supportati e se possibile, accoglierò volentieri.
Post aggiornato il 9 febbraio 2014 con l’aggiunta della nota numero 2 sul download del sistema operativo WiildOs per l’impiego della lavagna digitale a basso costo WiiLD.
Questo pezzo costituiva la prima di tre parti del prossimo post che si dovrebbe intitolare “Software libero e immagini – cos’è che fa la differenza”, ma mi stava palesemente prendendo la mano. Siccome l’argomento è cruciale, l’ho scorporato. Fra di voi vi sono alcuni studenti della IUL che si sono iscritti al prossimo appello di “Editing Multimediale”. Non ce più tempo per il prossimo post, che arriverà in settimana nuova e per quello successivo, su temi analoghi. Comunque, avendo visto il nostro concetto di corso e di esame espresso nel post precedente, confido nel fatto che tali studenti continuino a seguire le proposte successive attinenti all’editing. Ora è più importante soffermarsi su questo argomento.
In questo articolo glisso sulle differenze fra software libero e software open source, che sono invece rilevanti. Le abbiamo discusse in precedenza. Qui affrontiamo la questione alla larga.
L’evoluzione della cultura umana è punteggiata da una successione di discontinuità dirompenti, ognuna delle quali abbrevia drasticamente il percorso verso la successiva.
Nel 1993 l’antropologo Robin Dunbar ha pubblicato un articolo intitolato “Coevolution of neocortical size, group size and language in humans” [1] (Coevoluzione delle dimensioni neocorticali, della dimensione dei gruppi e del linguaggio negli umani). È un lavoro molto famoso perché è quello nel quale è stato definito il famoso numero di Dunbar, ovvero il numero di relazioni sociali che le capacità cognitive umane consentono di gestire – è un numero che sta fra 100 e 230, tipicamente 150.
Lo studio di Dunbar è famoso per il numero che porta il suo nome ma in realtà è pieno di considerazioni parecchio interessanti. Le scimmie si grattano, lo sanno tutti. Ma forse non tutti sanno che quella di grattarsi a vicenda è una pratica che ha un valore sociale importantissimo. Le scimmie sono animali sociali e lo sono perché questo ne facilita la sopravvivenza. La pratica di spulciarsi a vicenda – il grooming – è fondamentale per stabilire legami sociali importanti: io gratto te, che sei più grosso di me, così mi difendi quando quell’altro ignorante mi fa i dispetti… Nelle comunità di primati non umani si spende molto tempo nel grooming, fino al 15 del tempo totale, per comunità che arrivano fino a 30-50 individui. Più in là non si va. Dunbar stima che per arrivare ai valori tipici delle comunità umane, di 100-200 persone, il tempo dedicato al grooming supererebbe il 50
L’ipotesi di Dunbar è che il linguaggio sia comparso (anche) come sorta di grooming potenziato, sulla spinta di fattori ambientali che hanno favorito la formazione di comunità più ampie: per sopravvivere bisognava essere di più. È stato un passo micidiale: se gratto te non posso grattare anche un altro, ma se parlo posso rivolgermi a più compagni in un colpo! Non solo, il linguaggio ha anche generato un primo fondamentale livello di astrazione – forse già Lucy poteva sparlare con l’amica Lulù di quello screanzato che girava molto e portava poco… Una liberazione, la prima liberazione. Naturalmente, ogni liberazione apre nuovi mondi ma comporta nuovi rischi. Ciacolare troppo può essere pericoloso…
La seconda liberazione ha avuto luogo con la scrittura. Le civiltà antiche iniziano laddove appaiono i primi reperti scritti. Un formidabile potenziamento della trasmissione orale. Ma in particolare è l’alfabetico fonetico il passo fondamentale – 2000-1000 a.c., i Fenici, pare. La prima codifica di natura informatica: una ventina di simboli che combinati variamente possono esprimere qualsiasi concetto. Qui non è solo una questione di trasmissione, ma di espressione non più solo figurativa. L’alfabeto fonetico libera la via verso il pensiero astratto.
Il terzo passo è tecnologico ma non meno importante: la stampa – Gutenberg. I concetti astratti fissati nella scrittura possono essere distribuiti identicamente senza limiti. La comunicazione di massa ha preso le mosse alle soglie del rinascimento, lo catalizzò, con tutto quello che venne dopo.
Un passo dietro l’altro, ogni volta una spinta poderosa alla circolazione dell’informazione, ogni volta nuovi mondi. Fu Galileo a completare il successivo. Un passo lungo, sviluppato parallelamente a quello verbale, quello della matematica. Ma poi era rimasto intrappolato nella dicotomizzazione medievale della teoria e della pratica. Gli umanisti e gli scolastici dediti alla trasmissione delle verità, gli artigiani e i mestieranti vari si sporcavano le mani con la realtà. Michelangelo durò ancora non poca fatica ad elevare la scultura ad arte pura – troppa polvere. La matematica era sì ora astratta, ora strumento di calcolo, e poteva anche essere strumento di descrizione ma non linguaggio, non nel senso che rivelò Galileo: linguaggio per porre domande alla natura attraverso l’esperimento. La matematica a quel tempo era già tanta, e se l’alfabeto fonetico aveva consentito di fissare i costrutti astratti, la matematica consentiva di metterli a fuoco, di renderli nitidi e cristallini, più sicuramente trasmissibili, universali. Ma non era stata usata ancora per spiegare il mondo. Fu una fiammata, giusto quattro secoli fa, un attimo nella storia dell’umanità, divampa ancora, più impetuosa che mai. La conoscenza ha preso ad avanzare a passi da gigante. Una valanga: ogni due anni viene prodotta una quantità di conoscenza pari a tutta quella prodotta prima.
Tale conoscenza sedimenta strati fisici imponenti, composti di artefatti che a loro volta catalizzano la formazione di nuova conoscenza, in un ciclo con retroazione positiva – esplosione. Gli artefatti sono sempre più complessi – tecnologia. Non bastan più leve e pulsanti, per manovrarle c’è bisogno di qualcosa di nuovo. L’Apollo non sarebbe mai potuto arrivare sulla Luna. A far tutte le operazioni necessarie per vedere una singola TAC non basterebbe la vita di Keplero, che i calcoli li faceva da dio. Anche gli strumenti di indagine scientifica si sono evoluti – tecnologia per eccellenza. Le nuove macchine di indagine vomitano valanghe di dati. I calcoli matematici per interpretarli si son fatti troppo complessi, impossibili.
Ed ecco l’ultimo passo – il codice. Il linguaggio che serve per parlare con le macchine, per manovrarle e per elaborarne i risultati. Il codice lo pensa e lo scrive un uomo che vuole determinare il comportamento di una macchina, in tutti i suoi aspetti, quindi un ingegnere per esempio, o uno scienziato, certo. Ma oggi può capitare che anche un insegnante manipoli codice per realizzare il quiz di una pagina web per i suoi studenti. Oggi può capitare che anche un ragazzo di 12 anni possa realizzare una macchina in grado di leggere dati e fare cose, manipolandone il codice.
Il word processor è codice, l’orologio è codice, anche l’ABS dell’auto, praticamente tutto. Ma oggi il codice sbuzza fuori dalle macchine, lo possiamo toccare, è a disposizione, nel computer, in artefatti didattici, nel web, negli indirizzi URL, dappertutto. Ce l’abbiamo sotto il naso ma non ce ne accorgiamo quasi mai. La scuola non ha fatto tempo ad accorgersene, spesso nemmeno l’università. Usiamo tutto come fosse un ferro da stiro.
Linguaggio, scrittura, alfabeto fonetico, stampa, descrizione matematica, codice, ogni volta una spinta poderosa alla circolazione dell’informazione, ogni volta una liberazione per nuovi mondi. Ma quest’ultima volta c’è un ma.
Facciamo un passo indietro. Prendiamo un romanzo, “I vecchi e i giovani” di Pirandello per esempio. È scritto in italiano, ovvero un codice aperto e standard. Aperto perché la grammatica italiana è a disposizione di chiunque voglia impararla. Standard perché esiste una forma maggioritaria sulla quale i circa 65 milioni di italiani (4-5 risiedono all’estero) convengono e che la comunità internazionale riconosce come tale. Il testo del romanzo è disponibile con poca spesa – io, non so più come, ho l’edizione di certa “Editoriale Opportunity Book”, Milano 1995, £ 5000. Se voglio lo presto a un amico, poi a altri tre, poi lo regalo. Ne faccio quello che voglio. È scritto in italiano, ne copio dei brani, li studio – ne vale la pena: niente è cambiato… – li riuso nei miei scritti. La cultura viaggia sulle ali della libertà.
Poi ricevo un testo scritto da uno studente. Lui usa un sistema diverso dal mio, un sistema proprietario. Per leggerlo dovrei acquistare lo stesso software. Io ricevo testi da centinaia, migliaia di studenti. Su questi numeri capitano anche i casi più rari. Che devo fare: acquistare tutti i possibili software immaginabili, per tutti i possibili sistemi in circolazione? Oppure devo imporre ai miei studenti l’acquisto dei software e dei sistemi che uso io? Tutto regolare secondo voi?
Secondo noi no. E cosa faccio allora? Vado a vedere se in rete ci sono software di conversione dei formati liberamente e legittimamente disponibili. Mi potrei procurare facilmente le competenze tecniche per crackare i software proprietari che non posseggo ma non lo faccio, perché credo che il mondo vada fabbricato con soluzioni eticamente corrette. Se non trovo soluzioni legittime praticabili, invito lo studente ad andare a ripassare il capitolo dei software liberi e degli standard aperti, per poi ripropormi i suoi elaborati in una di queste forme, libere e legittime.
La questione dell’impiego del software libero, dell’open source se volete, e l’adesione verso gli standard aperti non è marginale, bensì rappresenta un elemento fondamentale per la cultura, la libertà d’espressione, l’etica sociale e lo sviluppo economico. Snoccioliamo un po’ di fatti.
Acquistando i software proprietari che vanno per la maggiore – Microsoft, Adobe, Oracle ecc. – contribuite ad elevare il prodotto interno lordo di un altro paese e perdete l’occasione di contribuire al vostro.
Copiando o crackando i software proprietari rubate.
Scaricando e utilizzando il software libero si contribuisce ad elevare la felicità interna lorda ed anche il prodotto interno lordo di molti paesi, inclusi il proprio.
Se io uso un programma proprietario di elaborazione delle immagini, diciamo Photoshop, e ho un problema, potrò provare a chiedere solo a persone che posseggono Photoshop. Altri amici culturalmente in grado di provare ad affrontare lo stesso problema non potranno cimentarsi e collaborare – difficilmente acquisteranno una licenza del software solo per questo motivo e se sono onesti, non utilizzeranno nemmeno una copia rubata. Se invece uso un programma di elaborazione di immagini libero, diciamo Gimp, avrò a disposizione un mondo sterminato di persone in grado di darmi una mano.
Il modello proprietario impone l’onere della globalizzazione brutale. Poteri economici inarrivabili determinano cosa puoi fare a casa tua, cosa e come puoi fare con il software, quando lo devi aggiornare, quanto lo devi pagare. Tutto ciò nella migliore delle ipotesi: può anche succedere che il software compia operazioni che non tutti gli utenti potrebbero gradire, come raccogliere informazioni all’insaputa dell’utente o gestire in modo non trasparente i formati dei file. Un caso tipico era Word, che lasciava nascoste nel documento versioni del testo successivamente cancellate dall’autore, il quale inviava a sua insaputa il file con informazioni che un esperto avrebbe potuto vedere e che magari avrebbero potuto creare imbarazzo.
Il modello libero invece consente di unire gli aspetti positivi della globalizzazione al valore della localizzazione. Un caso tipico è quello dell’adattamento dei software alle lingue minoritarie o emarginate dall’economia occidentale. Cerco a caso fra le notizie più recenti. In Global Voices – sito che raccoglie notizie da tutto il mondo al di fuori della stampa ufficiale (mainstream information – trovo Un correttore ortografico per la lingua Bambara:
Il correttore ortografico è disponibile in programmi per testi e ufficio open source come OpenOffice, LibreOffice, NeoOffice per computer Windows, Mac e Linux. Come è stato possibile ottenere questo risultato? In primo luogo grazie alla pubblicazione online dell’enorme lavoro fatto dai linguisti, autori di dizionari e grammatiche, e poi alla collaborazione fra linguisti e specialisti di IT che hanno condiviso il sogno di disporre di un correttore in Bambara. La lingua Bambara è parlata da 3 milioni di persone in Mali, Burkina Faso, Costa d’Avorio, Senegal, Gambia, Guinea, Sierra Leone e Ghana.
Per inciso, una ventina d’anni fa ho collaborato con un fisico ghanese, John, caro amico che ricordo con affetto, molto bravo e di gentilezza rara. Mi rammento anche delle difficoltà che aveva, quando si trovava in Ghana, a leggere i file in Word che molti occidentali gli inviavano con versioni del software più recenti che là non si potevano permettere. Stesso identico problema con Natascia, anche lei un fisico, di Novosibirsk, anzi più precisamente di Akademgorodok – Академгородок, lei mi diceva orgogliosa “Città della Scienza” – altra persona amabile.
Conoscenza e cultura viaggiano sui canali liberi. E anche la giustizia, di conseguenza.
In Spagna è in atto da diversi anni un processo di diffusione dei sistemi linux nella pubbliche amministrazioni delle regioni svantaggiate. Esistono distribuzioni di Linux che sono state personalizzate localmente: LinEx per Extremadura, Trisquel per la Galizia, Asturix per l’Asturia, lliurex per la comunità di Valencia e Guadalinex per l’Andalusia.
Il caso di Extremadura è particolarmente interessante. Il governo di questa regione, notoriamente afflitta da condizioni di sottosviluppo particolarmente gravi, all’inizio dell’anno scorso annunciò il passaggio dei 40000 computer dell’amministrazione a software open source.
Gli amministratori di quella regione hanno quindi messo in pratica ciò che è noto ormai da tempo, ovvero che sostituendo software open source al posto di quello proprietario si possono realizzare risparmi significativi. L’operazione comporta l’impiego di una distribuzione di Linux – chiamata Sysgobex – adattata alle esigenze amministrative locali.
Il risparmio stimato è dell’ordine di 30 milioni di Euro l’anno. L’iniziativa segue una serie di esperienze precedenti: 70000 computer nelle scuole secondarie, 15000 computer nell’amministrazione sanitaria, 150 computer Linux in vari ministeri.
Vi sono altre iniziative di portata simile in Europa: 70000 computer adottati dalla polizia francese, 13000 computer dall’amministrazione comunale di Monaco di Baviera.
L’Italia purtroppo è un paese particolarmente fermo e tristemente sordo alle innovazioni, quelle buone. Il ciarpame no, quello lo assorbe a meraviglia. Ma non si deve generalizzare, i focolai di vita ci sono, forse più radi di quello che si desidererebbe, ma ci sono. A volte addirittura a livello istituzionale. C’è l’esempio dell’Azienda Usl 11 di Empoli, dove nella maggioranza dei casi i server sono Linux e la suite di software per ufficio adottata è Libreoffice, su tutti i 2000 computer dell’azienda. Davvero un buon risultato anche se certamente episodico, malgrado la Direttiva Stanca per l’open source nella Pubblica Amministrazione, del 2003.
Ma quello che dobbiamo fare è rendersi consapevoli delle innumerevoli realtà positive di cui il Paese è miracolosamente ricco, opera di gente competente e appassionata che vive e lavora nonostante il contesto istituzionale devastato; agiamo quindi su quelle realtà, cerchiamole, intrufoliamoci, aiutiamole, diffondiamone la notizia. Esistono i Linux User Group, i Fablab – questo è quello di Firenze – il mondo del coworking, giusto per menzionare alcune realtà, estremamente vitali, pervasive e soprattutto, interamente gestite da giovani. È lì che dobbiamo andare e co-operare, invece di sentenziare dai nostri scranni alla deriva.
In seguito approfondiremo e entremo nei dettagli di queste attività. Ora però citiamo un’attività che è particolarmente interessante per questo laboratorio: il caso di WiildOs [2], una distribuzione di Linux costruita intorno alla lavagna digitale di bassissimo costo realizzata con il telecomando Wiimote e pensata per insegnanti italiani, perché fatta da giovani italiani – qui la storia. Invito tutti a esplorare questi link e anche la Mappa di riferimento delle scuole e degli insegnanti che utilizzano software libero nella scuola. Torneremo presto sull’argomento.
[1] R.I.M. Dunbar (1993) “Coevolution of neocortical size, group size and language in humans”, Behavioral and Brain Sciences, 16: 681-735.
[2] Gli sviluppatori del progetto WiildOs stanno ristrutturando l’organizzazione e la distribuzione del software. L’obiettivo è quello di poter offrire in estate una versione di Ubuntu con tutti i pacchetti che compongono il progetto WiildOs, al fine di offrire una distribuzione didatticamente valida e ancora più stabile. Tuttavia è già possibile sperimentare una buona versione di WiildOs: file ISO – 2.3 GB – per chi sa cos’è, la stringa di controllo MD5 dell’integrità del download è 102405f525771f2d02802dfc245d8459. Attenzione però, installare un sistema operativo non è come installare un singolo software, come potrebbe essere LibreOffice. Sebbene non sia una cosa trascendentale richiede un minimo di dimestichezza con operazioni del genere oppure la disponibilità di qualcuno che sia in grado di dare eventualmente una mano. In ogni caso, prima di installare un certo sistema operativo su una certa macchina, occorre fare un indagine in rete su eventuali esperienze preesistenti, relative all’installazione di quel sistema su quella macchina. In futuro cercheremo di approfondire questo tema.
Questo laboratorio è esposto al pubblico dominio e vi può partecipare chiunque. Questa è la sua ricchezza. Ma la tempo stesso, capita che vi vengano ospitati dei corsi istituzionali. Ecco che, in prossimità delle date degli appelli, gli “studenti istituzionali” inizino a scrivere chiedendo – Ma che succederà all’esame?
Tanto vale che risponda una volta per tutte, nel modo che segue.
Nella nostra visione della formazione gli esami giocano un ruolo del tutto marginale, in questo tipo di corsi se ne potrebbe fare tranquillamente a meno.
Tutto ciò che vedete accadere è immaginato per smuovere le persone, per indurle a studiare e a tradurre subito in azioni pratiche ciò che hanno studiato, al fine di acquisire competenze che siano effettivamente riutilizzabili. Potremmo dire: impara a fare a qualcosa, non importa cosa – entro certi limiti – purché tu la sappia mettere a frutto nella tua realtà.
Si cerca quindi di creare situazioni in cui la gente sia costretta ad agitarsi, a inventarsi qualcosa da fare. La varietà e vaghezza delle indicazioni procedurali è voluta, in un disegno dove lo smarrimento iniziale è necessario alla generazione dell’atteggiamento psicologico corretto – positivo, fattivo, creativo. Si cerca di incuriosire, centellinando stimoli variegati che possano avere un senso nel contesto dell’insegnamento.
Non si vuole però che gli studenti anneghino in qualche stagno di microcompetenze effimere – lo stagione cambia sovente di questi tempi, magari domani, là in quel secco, ci sarà uno stagno nuovo e questo qui sarà invece già scomparso. No, nella nostra visione le competenze tecnologiche si inquadrano in un atto formativo di natura umanistica. Le competenze devono sempre essere tese alla valorizzazione e alla crescita dell’uomo, devono essere collocate in un paesaggio etico ben definito, devono essere sostenibili nel tempo e autorigeneranti.
Non affogare in uno stagno di microcompetenze, bensì nuotare nell’oceano della conoscenza e dei suoi strumenti in divenire. Il metodo si basa sulla ripetizione di uno schema immersione-emersione, particolare-generale, dettaglio-big picture. Lo schema viene ripetuto ciclicamente, quante volte possibile nei tempi dati, campionando con sufficiente regolarità e ampiezza il dominio della disciplina in questione. Si abdica all’ormai sterile e anacronistico proposito di dare conoscenze preconfezionate e stardardizzate che siano valide per tutti. Ci si propone invece di stendere l’ordito fra particolare e generale, sul quale ciascuno dovrà tessere la propria trama, che dipenderà personalità, preparazione culturale, contesto professionale e obiettivi.
Nello specifico dei corsi istituzionali ospitati in questo laboratorio, al momento dell’esame finale, noi abbiamo tutte le informazioni che servono per l’attribuzione della valutazione richiesta dal sistema. Tecnicamente la cosa è resa possibile dal fatto che in internet le informazioni sono naturalmente persistenti – l’unica accortezza importante sta nell’utilizzare strumenti e codifiche che siano aperti e standard. In quei casi in cui le informazioni si rivelano essere insufficienti per la scarsa attività, molto semplicemente allo studente viene suggerito di proseguire ancora un po’, con le dritte del caso.
Quando invece le attività sono sufficienti o – non raramente – ridondanti, l’esame viene sì svolto nei contesti previsti istituzionalmente, ma anziché essere condotto secondo lo schema usuale domanda-risposta, si risolve in una discussione sugli accadimenti, tesa a fornire ai docenti un feedback utile sull’andamento del corso. In due parole: il proprio voto lo studente se lo fabbrica nel percorso, il voto dell’esame è in realtà un voto dato ai docenti!
Note bibliografiche
Gli ingredienti di una ricetta devono rinascere nel nuovo della pietanza, irriconoscibili seppur necessari. Qui, fra tanti altri, gli ingredienti fondamentali sono: